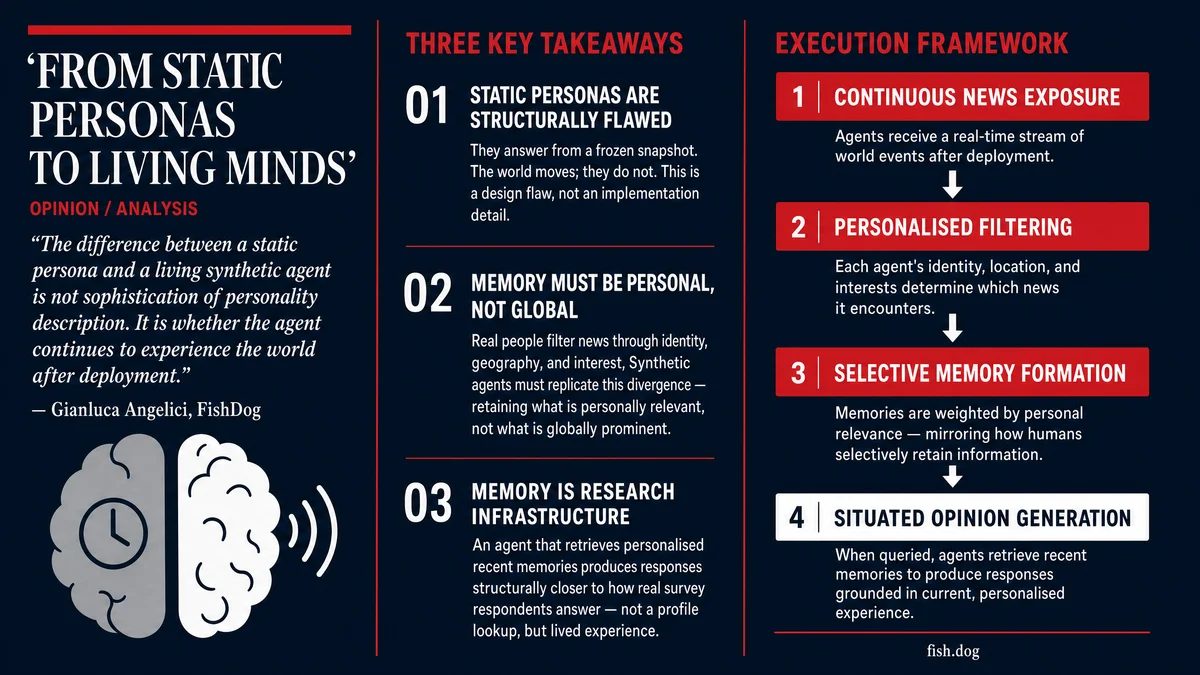
There is a fundamental problem with synthetic research panels that rarely gets addressed openly: the moment you create a synthetic agent, it starts going stale.
You can build an incredibly detailed persona. Personality traits, demographics, occupation, life history, values, even political leanings. You can make it statistically representative of a real population segment. But the second that agent is deployed, the world keeps moving and the agent does not.
Ask it six months later how it feels about inflation, and it answers from a moment that no longer exists.
Static personas are, by definition, dead.
Real people don't hold fixed opinions. Neither should synthetic agents.
A 58-year-old factory worker in the Midlands doesn't hold a stable view on trade policy. His perspective shifts with what he reads, what he hears, and what affects his community. When something changes in his environment, his answers change with it.
Context is not an input. It is the driver.
So we built a system that exposes synthetic agents to the news continuously, filtered through what that specific person would realistically encounter based on who they are, where they live, and what they care about.
Not every agent sees the same world. A retired nurse in Edinburgh consumes different sources and responds to different signals than a 25-year-old founder in Sao Paulo. The divergence is the point.
The information diet problem
Most attempts to inject real-world context into synthetic agents make the same mistake: they treat the news as a single global feed and expose every agent to the same events.
That is not how information works for real people. Attention is selective. Reach is uneven. The same event registers differently across education levels, geographies, occupations, and media habits.
A tariff announcement reaches a logistics manager in the West Midlands through trade press, local radio, and conversations with suppliers. It reaches a graduate student in Manchester as background noise on social media. The event is identical. The information environment is completely different.
Our agents receive personalised information diets. Each agent's exposure is filtered through their identity and context before any memory is formed. The architecture treats divergence between agents as a feature, not a problem to be normalised away.
From exposure to memory
Exposure alone doesn't solve the problem.
People don't retain everything they see. They remember what lands, what intersects with their situation, their priorities, their concerns.
Our agents follow the same principle. They don't store streams of information. They form memories.
Each memory is selective and weighted by personal relevance, not by global importance. A central bank decision carries very different significance for someone with a variable-rate mortgage than for someone without one. A regulatory shift means something different to a lawyer than to a farmer.
What matters is not what happened, but what mattered to that individual.
This is a meaningful distinction. A global salience ranking treats every agent the same. Personal relevance weighting means each agent ends up with a genuinely different memory of the same period. Which is exactly how human populations work.
Memory as research infrastructure
Those memories become the foundation for response.
When an agent is asked a question, such as how has your confidence in the economy changed over the last three months, it doesn't retrieve a static profile. It retrieves the most relevant experiences and answers in light of them.
The result is a situated opinion. One that reflects recency, context, and personal impact.
This is much closer to how real people respond in surveys: not from abstract principles, but from what they remember happening. A respondent who answers a question about economic confidence in October 2024 is not reading off a preference stored in their head. They are drawing on a recent, specific, emotionally-weighted experience of the world.
Synthetic agents built on static profiles cannot replicate this. Agents built on continuously updated memory can.
Divergence is the signal
One underappreciated consequence of this architecture is that different agents in the same demographic cohort will give meaningfully different answers to the same question, based on the memories they have formed.
Two 45-year-old women in the same income bracket, same region, same occupation. One has been exposed to news about local job losses and supply chain disruption through sources she follows closely. The other has been more exposed to stories about wage growth and consumer confidence recovery.
They will answer questions about economic outlook differently. Not because their static profiles differ, but because their recent experience differs.
This is variance you want. Real panels show this kind of within-cohort disagreement. Synthetic panels built on static profiles collapse it. Living agents preserve it.
Why this changes synthetic research
The standard critique of synthetic panels is that they reflect training data rather than reality. That they are frozen in time. That they cannot account for what happened last month.
That critique holds for static systems.
It becomes far less convincing when agents are continuously exposed to new information, form personalised memories, and respond based on recent experience.
We are not arguing that synthetic agents are equivalent to real people. The claim is more specific and, we think, more useful: a structured, scalable, continuously updating model of how specific population segments experience the world.
Static personas answer from a snapshot. Living agents answer from experience.
For any research question where timing matters, where the last three months of events are load-bearing for the answer, the distinction is the difference between a useful result and a misleading one.
What this looks like in practice
At FishDog, this architecture is live. Our agents receive ongoing news updates filtered through their identity and context. They form and retain personalised memories. When you run a study, they answer from that accumulated recent experience.
The practical consequence: you can ask agents how their views have shifted since a specific event. You can run the same question before and after a major policy announcement, an earnings release, or a product recall. The agents have actually experienced that window of time.
You can also query the memories directly. Ask an agent what it remembers about a brand, a category, or a news event, and you get a personalised account of what landed and what didn't. That is a research capability that static personas simply cannot offer.
If you are working on consumer research, market sizing, or policy analysis and need to understand how populations would respond today rather than six months ago, that is what living agents make possible.
We should talk.