
A confession
I shipped some code last week that I do not fully understand.
This is not, I should say at once, a confession of negligence. The code passes its tests. It has been reviewed. It does what the product brief said it should do. It certainly works. What I mean is something more specific, and more uncomfortable: the agent that wrote it operates with a context window larger than mine, synthesises across more material than I can hold in my head, and arrived at a structure that I could spend an afternoon reading and still not be confident I'd caught every implication.
I am, by most measures, reasonably bright. I have founded companies. I have written software professionally. I am familiar with the codebase. And I have come to the conclusion, slowly and with some reluctance, that I cannot meaningfully QA the work product of a frontier LLM operating at the limits of its capability.
This article is about what I did about that.
The short version: I gave up trying to be the second brain. I added a second AI agent instead.
The realisation that broke my model of how this is supposed to work
Most discussion of working with AI coding agents still assumes a particular shape. The human is in the loop. The human reviews the diff. The human catches what the agent got wrong. The agent is a productivity multiplier on top of an essentially human process.
This was true, broadly, of the LLMs of 2024. It was getting strained by mid-2025. By the time Claude Code shipped to terminals in December 2025, and certainly by the spring of 2026, it has stopped being true in the way it was meant to be true.
Working day-to-day with Codex (ChatGPT's VS Code plugin - typically GTP-5.4) on a non-trivial codebase, I started to notice something that I did not particularly want to notice. The agent was, plainly, more capable than me at the specific task in front of us. It could read forty files in the time it took me to open one. It could hold the whole architecture in working memory while reasoning about the change. Its first draft of a function was, more often than not, better than what I would have written on a third attempt. When I disagreed with it, I was, on inspection, wrong about half the time.
I want to be careful here, because this is the sort of statement that invites either dismissal or hand-wringing. I am not claiming the agent is conscious. I am not claiming it is creative in some mystical sense. I am claiming, narrowly and operationally, that on the specific axis of producing high-quality code in this codebase, given this brief, in this hour, it has comprehensively overtaken me. This is a statement about throughput and depth, not about general intelligence.
Once you accept this, an awkward question follows.
If the agent is producing work that exceeds my capacity to fully verify, what is my review actually doing?
In practice, my review was doing something narrower than I'd been telling myself. I was checking: does this look reasonable. Does it match the brief at a structural level. Does it not contain anything obviously alarming. What I was not doing, and could not do, was independently arrive at the same set of conclusions the agent had reached and validate them point by point. The work was beyond me. My approval was a vibe.
This is, I think, the position quite a lot of engineers find themselves in now, whether or not they say so out loud.
You cannot QA what you cannot understand
The standard response to this problem, in the literature and in conference talks, is that the human needs to understand more. Read the code more carefully. Spend more time. Ask better questions. Develop deeper expertise. Be a better human.
I have a great deal of respect for this position and I think it is wrong.
It is wrong in two specific ways. The first is empirical: the gap between human cognitive throughput and frontier LLM cognitive throughput is widening, not narrowing. Whatever proportion of agent output a careful human can verify today, that proportion will be smaller next year. The advice "read more carefully" does not scale against an opponent that reads at a hundred times your speed and remembers all of it. We are, on this trajectory, eventually telling humans to outrun a car on foot.
The second is structural. Even where a human could in principle verify the work, the time spent doing so largely cancels the productivity gain that brought the agent in in the first place. If a senior engineer is going to read every line of every diff with the depth required to catch subtle bugs, you have not built a faster engineering team. You have built a team that produces code at the speed at which a senior engineer can read it. Which, mostly, is the speed at which a senior engineer could have written it.
The trap is that you think you've sped up. You have, in fact, just moved the bottleneck inward, into a single human, and made it less visible.
There is a second failure mode that is, if anything, worse. It is the failure mode of pretending. The senior engineer, faced with a thousand-line diff produced in twelve minutes by an agent, does not have time to read it properly. They skim. They glance. They run the tests. They approve. The code goes in. Whatever bug the agent embedded, structural or subtle, ships with it. The signal that "a human approved this" is doing work it cannot do.
I had, by sometime in March, accepted that I was running this failure mode. I was approving code I did not really understand. The tests passed. The feature worked. But I was not, in any honest sense, the second pair of eyes that I was claiming to be.
So I stopped claiming.
Fight fire with fire
The thing that can verify the work of a frontier LLM is, plainly, another frontier LLM.
This is not a clever observation. It is the obvious one once you let go of the assumption that humans must be the verification layer. If the problem is that the work product exceeds human cognitive throughput, the answer is to put it through something with comparable throughput. The answer is a peer.
What changes when you stop trying to be the peer and bring one in is, in my experience, dramatic. Not in some vague qualitative way. In a measurable, day-to-day, my-bug-rate-fell way.
The setup I have arrived at, after about four months of fiddling, is this. Claude is the product manager. Codex is the developer. They review each other's work, in writing, in markdown, in shared folders. They go through structured loops. They explicitly critique. The human, which is to say me, is involved at three points: setting the original brief, arbitrating where they disagree, and answering the small number of questions that neither can resolve from context.
Most of the friction has gone out of the system. Most of the bugs, too. I will tell you why I think this works, and then I will tell you exactly how it works, because the second is more useful than the first.
A note on what is actually new
I should acknowledge, before going further, that the mechanic I am about to describe is no longer unusual. Hamel Husain has shipped a `claude-review-loop` plugin that automates exactly this handshake. OpenAI ships an official `codex-plugin-cc` that wires the cross-provider review into Codex by default. Visual Studio Code, in February 2026, repositioned itself as "your home for multi-agent development." Addy Osmani has written persuasively about the "orchestrator versus conductor" mental shift. The dual-agent loop is, by mid-2026, on its way to being standard practice.
The argument I want to make in this article is upstream of the mechanic. It is not that this is a useful workflow, although I think it is. It is that, given the trajectory of frontier-model capability, peer-LLM verification is the only verification layer left that scales. Treat what follows as an epistemic argument about what has happened to the meaning of "human in the loop", not as a productivity tip.
Why role assignment matters
The first thing that surprised me about this setup is how much depended on giving each agent a stable role. I had assumed, naively, that you could put any frontier model on any task and get roughly equivalent output. This is not what I found.
What I found is that trust accrues unevenly. I came to trust Codex with code in a way I did not trust Claude with code, not because Claude is bad at code, but because Codex lives in the IDE, sees the repo, runs the tests, and operates inside the substrate where code actually lives. Claude, conversely, is the better synthesiser of disparate research, the better writer of long-form prose, the better reasoner over fuzzy product trade-offs. It can read forty interview transcripts and produce a thesis. It is, frankly, a far better product manager than I am.
So I let them be those things. Claude does product. Codex does code. I do not, on most days, let Claude touch the codebase, and I do not, on most days, ask Codex to write a product brief from cold. They cross the line only to critique each other's work, which is exactly the role that benefits from a perspective from outside the artefact.
This is, on reflection, simply the same logic that applies to human teams. You hire a product manager and a developer because they bring different lenses to the same problem. The lenses being different is the entire point. If you replaced the developer's lens with another product manager's lens, you would not get a better product brief. You would get a worse software product, because nobody was applying the developer's lens.
The same is true here. Claude and Codex are not interchangeable. They have, to whatever extent these terms apply to large language models, different temperaments. They notice different things. They miss different things. The point is precisely the difference.
How the loop actually runs
Here is the workflow as I run it on a typical feature.
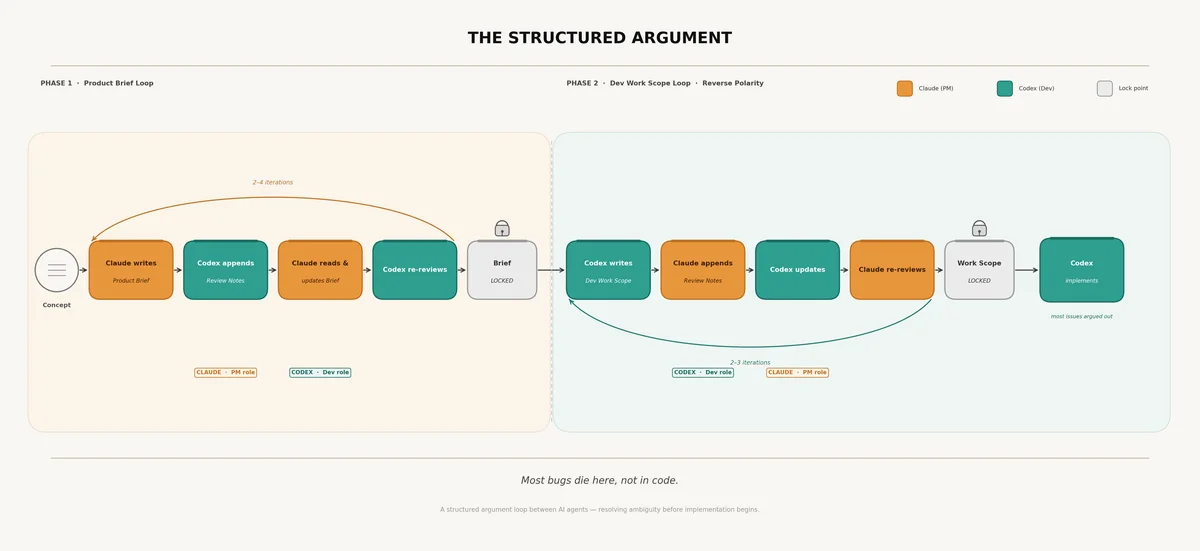
I begin with a concept. Sometimes this is a problem, sometimes a UI sketch, sometimes a screenshot of an existing flow with a complaint about it. I hand the concept to Claude. Claude writes a product brief. I read it. The first draft is usually structurally correct, occasionally inspired, and contains at least one assumption I want to challenge.
Rather than challenge it myself, I hand the brief to Codex. Codex reads it. Codex's instructions are explicit: read the brief, identify gaps, identify implementation issues, identify places where the logic does not match what the codebase currently does, and append your notes at the bottom of the same markdown file. Do not edit the brief. Do not rewrite it. Append.
Codex returns its review. I read it. I almost always learn something. Codex catches things Claude missed because Codex sees the codebase that Claude does not. The brief assumes a database schema that has changed; Codex notices. The brief specifies a UI element that already exists with subtly different behaviour; Codex notices. The brief defines an edge case the existing system already handles; Codex notices.
I hand the annotated brief back to Claude. Claude reads its own brief, reads Codex's notes, and produces a revised brief. Then back to Codex for a second pass. Then back to Claude. Two to four loops, typically. The brief at the end of this is, demonstrably, much better than the brief at the beginning.
Then we reverse the polarity.
The locked brief goes to Codex, which writes a developer work scope. This is a separate document. It is not the product brief. It speaks in implementation terms: which files change, which tests need writing, which database migrations are required, which APIs are affected. The product brief is for the user. The work scope is for the machine.
Claude now plays the role Codex played before. Claude reviews the work scope. Claude appends notes. Codex updates. Claude re-reviews. Two to three loops. The work scope at the end is, again, materially better than at the start.
Only then does Codex implement. By the time we get to actual code, the agents have already worked through the design space twice. Most of what would have been bugs has been argued out in markdown. The implementation is, in the cliché, the easy part.
There is one further step that I have come to insist on, which is each agent reviewing its own work. Before declaring a brief or work scope finished, I ask the agent: is this high-quality enough that a developer can implement it accurately, cleanly, and quickly? Roughly a third of the time, the answer is no, and the agent itself surfaces what is missing. I have not yet stopped being startled by how good agents are at noticing the weaknesses in their own output, when asked to.
The deeper claim
It would be reasonable to read all of this as a productivity hack and stop there. Phillip uses two agents instead of one. Bug rate drops. Useful tip.
I think it is more than that.
The substantive claim, the one that I think generalises beyond my particular setup, is this. The blind spots of a large language model are not random. They are systematic. They are functions of the training data, the architecture, the post-training objectives, and the deployment context. A different model, trained by a different lab, on different data, with different objectives, has different blind spots. The intersection of two such blind-spot sets is, by construction, much smaller than either alone.
This is why a second human reviewer catches things the first one missed. It is also why two humans from the same engineering culture, trained on the same patterns, miss the same things. The benefit of a reviewer is not the existence of a second brain. It is the existence of a differently configured second brain.
The same logic applies to LLMs, with one extra wrinkle: the labs themselves are working hard to differentiate their models. Anthropic and OpenAI are not building the same product. Their respective models do not fail in the same ways. This is, somewhat ironically, a gift to anyone running a multi-agent QA setup. The market has produced, for its own competitive reasons, a set of frontier models with usefully orthogonal failure modes.
There is, I should acknowledge, a serious counter-argument here. A 2026 paper, Rethinking LLMs as Verifiers: When Verification is Harder Than Solving, shows that LLMs are, on a range of formal benchmarks, measurably worse at verifying solutions than at producing them. If true, this would seem to undermine the entire premise of using a peer LLM as the verifier.
I find the paper persuasive on its own terms and unpersuasive as an objection to what I am claiming here. The reason is asymmetry. The paper measures LLM-verifier performance against ground truth. It does not, and cannot, measure it against the only realistic alternative on a frontier-LLM-produced artefact, which is a human reviewer. Peer-LLM verification is imperfect. Human verification, at the speed and depth required to keep up with frontier-LLM output, is worse. The relevant question is not "is the LLM verifier perfect" but "is the LLM verifier better than the next-best alternative". On any non-trivial codebase produced at frontier-LLM speed, it is. The gap, by my reading, widens with capability.
The implication is straightforward. As models get more capable, the gap between what they produce and what a human can verify will widen. The only verification layer that scales with model capability is a peer model. Not a smaller model. Not a fine-tuned validator. A frontier model from a different lab, asked to think differently about the same artefact.
This is the architecture I think most serious AI-built software will end up running on within eighteen months, whether or not anyone calls it that.
What this changes
Quite a lot, actually.
It changes the role of the human. The human is no longer the verification layer. The human is the source of the original brief, the arbitrator of irreducible disagreements, and the answerer of questions that require corporate context the agents cannot have. The human is, in effect, more like a chief technical officer than a senior engineer. Sets direction, settles arguments, owns the strategy. Does not, in any meaningful sense, write the code or even check the code line by line.
It changes the meaning of "human in the loop." The phrase, as it is most commonly deployed, conjures an image of a human who reads each output and approves or rejects it. This is the model that breaks at frontier capability. The version of "human in the loop" that survives is much narrower: a human who arbitrates between agents and answers the few questions the agents themselves flag as out-of-context. Most of the loop, by volume, no longer touches the human at all.
It changes, finally, the orientation toward the agent's intelligence. There is a school of thought, currently fashionable, that recommends deliberately throttling LLMs back to the level a human can verify, on the grounds that any output beyond that level is unsafe to ship. I understand the impulse and I think it is, in the long run, a losing position. The frontier moves whether you ride it or not. The competitive answer is not to slow your agents down. It is to give them a peer.
A note on the unease
I do not, for the avoidance of doubt, fully love this conclusion.
I quite liked being the smartest person in a company. I quite liked having opinions about the code that the code was obliged to take seriously. I quite liked the model in which the human was the indispensable cognitive layer and the machines were the productivity tools. That model was, in retrospect, an artefact of LLMs being weaker than they now are.
The new model is uncomfortable in the specific way that being out-thought is always uncomfortable. It is, however, accurate. And accuracy is, in my experience, the only useful place to start.
Two agents. One human. Each agent doing what it does best. Each agent checking the other. The human stepping in when, and only when, the agents themselves cannot resolve the disagreement.
This is the architecture I have been running for four months. The code is better. The bugs are fewer. The product moves faster. I am, on most days, doing less work than I have done at any point in my career, and shipping more. I am also, separately, exhausted, but that is a different article.
For now: stop trying to QA your frontier coding agent yourself. You can't, and pretending you can is the riskier position. Bring in a peer. Let them argue. Read the result.
It is the only verification layer left that scales.
Phillip Gales is the founder of [FishDog](https://fish.dog), a synthetic market research platform. This is the first in a six-part series on building software with AI agents. The next piece — Anatomy of an AI-Built Product: 21 Days, 40 Hours of My Time, 128,506 Lines of Code — walks a real product build through eight stages, from concept through to release notes.