
By Phillip Gales · May 2026
The morning I became a message queue
One Saturday in March, I caught myself opening Claude on one screen, copying a 4,000-word product brief out of it, pasting it into Codex on another screen, asking Codex to review it, waiting for Codex to finish, copying the review out of Codex, pasting it back into Claude, asking Claude to revise. For thirty-five minutes, this is what I did. The agents wrote. I shuttled. The agents wrote some more. I shuttled.
I realised, somewhere around the third copy-paste cycle, that I had become the protocol between two large language models. I was the network layer. I was the message queue. I was, on closer inspection, doing a job that any sufficiently competent third LLM could do better, faster, and without watching YouTube documentaries between turns.
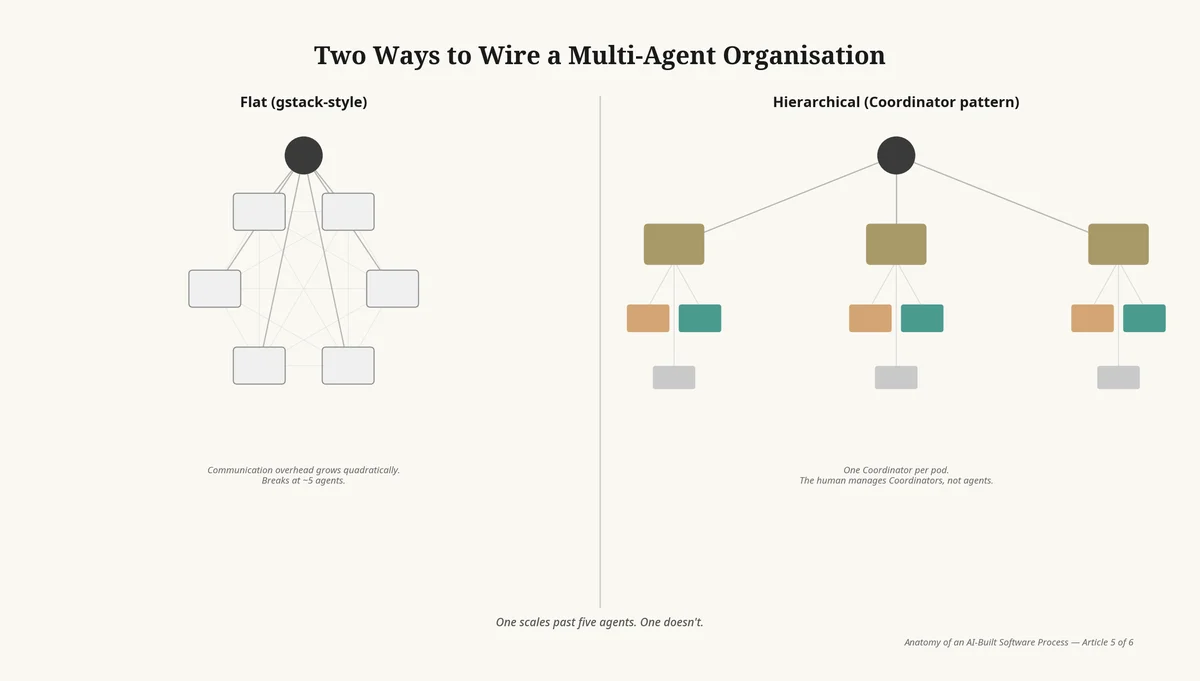
This article is about what happened when I gave that job to a third LLM. The new role I am going to call the Coordinator, because nothing in the existing vocabulary fits and because the discipline that scales it deserves a name. The argument, more broadly, is that the organisational shape AI-built companies are converging on is hierarchical, not flat. The flat-team patterns currently fashionable in the agentic-engineering literature — Garry Tan's `gstack` being the most prominent — do not, in my experience, scale past about five agents before the human at the top falls over. The Coordinator pattern is the alternative I think most serious founder-led AI engineering will end up running on within eighteen months. This article is what it looks like and why.
The middleman bottleneck
The first three pieces in this series described a pipeline in which I sit between two AI agents. Claude writes briefs. Codex critiques them. I read the critique, hand it back to Claude, watch Claude revise, hand the revision back to Codex, and so on through two to four cycles. The same pattern reverses for the work scope. The same pattern, broadly, characterises the product unit test layer and the implementation step.
This works, for one pipeline at a time, beautifully. It produces the output documented in the second piece: 128,506 lines of code in twenty-one days from forty hours of human attention. The pipeline is, by any reasonable measure, working.
The catch is that it is one pipeline. The agents produce work in roughly thirty-minute bursts; for each burst, I am needed for, say, two to five minutes of decision-making and artefact-shuttling. The remaining twenty-five minutes per burst, I am, in principle, free. In practice, I am not free, because (a) the agents will run idle waiting for me if I context-switch away, and (b) the moment I come back, I need full context on what they were doing, which takes longer than two to five minutes to reconstruct.
The result is that I run, in practice, two pipelines at once on a good day and one pipeline at once on most days. Forty hours of my attention buys me two pipelines' worth of output. Not four. Not eight.
A founder running four pipelines at once would, in this configuration, need someone else to shuttle artefacts on the other three. The someone-else can be, and on inspection should be, another agent. Specifically, an agent that can:
Hold the high-level objective for a pipeline.
Recognise when an artefact is ready for the next reviewer.
Route artefacts between Claude and Codex without my involvement.
Surface to me only the questions that genuinely require me — architectural ambiguities, irreducible disagreements, corporate-context questions the agents do not have.
Maintain state about which pipelines are in flight, where each is, and what is blocked on what.
That is the Coordinator. It is not a new agent in the sense of a new model; in our pipeline, it is Claude or Codex run with a different prompt, kept in a separate conversation, given the orchestration role. Sometimes we run a third vendor's model as the Coordinator specifically to give it different blind spots from the agents it is coordinating. The instruction set is roughly: you are not writing the brief; you are not writing the code; you are running the pipeline. Hand the brief to the brief-writer. Hand the brief and any reviews to the brief-reviewer. Track which cycle we are on. Surface decisions to the human only when the agents themselves cannot resolve. Otherwise, continue.
What that single change unlocks is the rest of this article.
The pod
A pod in this model is a self-contained engineering unit, one feature wide. It has, at minimum, three agents:
A Coordinator, running the pipeline and routing artefacts.
A product agent — Claude, in our pipeline, in the PM role described in the brief loop article.
A dev agent — Codex, in the developer role.
A more capable pod adds two more agents:
A synthetic-user agent — in our pipeline, a FishDog API call the Coordinator invokes when the pod needs user-perspective validation on the locked brief or against a product unit test.
A QA agent — Claude in a different conversation, running the product unit test suite via a headless browser, reporting failures back to the Coordinator.
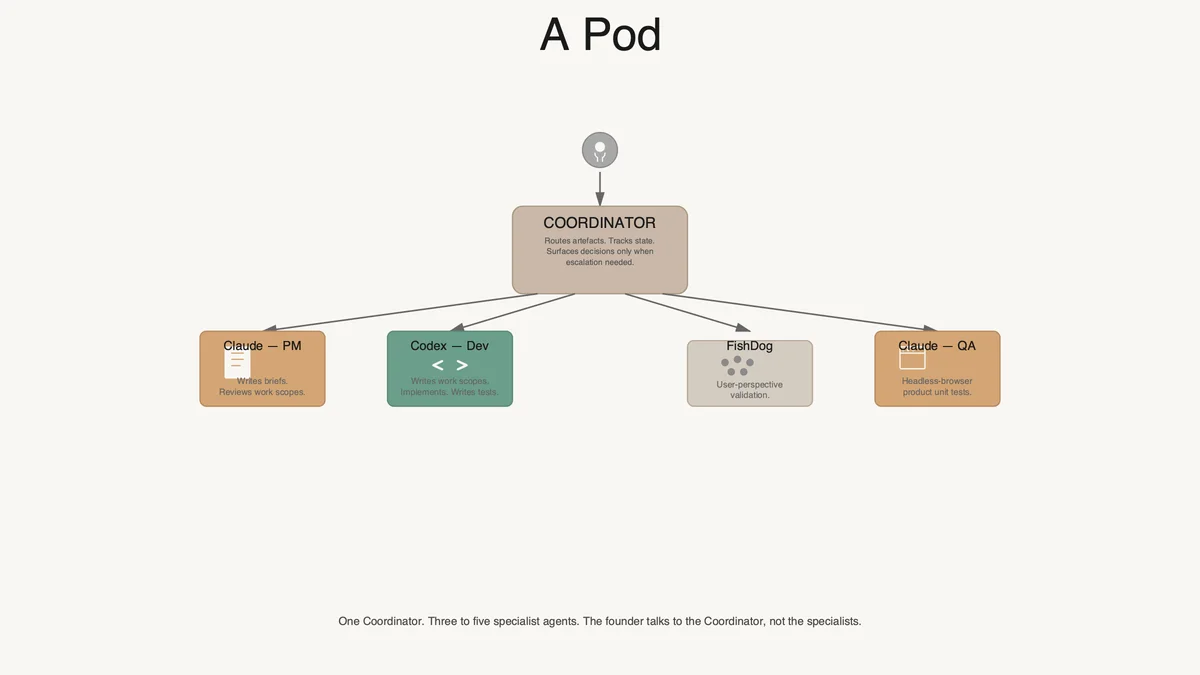
That is one pod. It runs one feature, or one workstream, end-to-end. Concept goes in at the top; production-ready code comes out the bottom; the brief, work scope, tests, and release notes are produced as artefacts along the way. The human is involved at the gates — concept, locked brief, locked work scope, sign-off — and at the rare irreducible decision. The Coordinator handles everything else.
The number of pods you can run, as a single founder, depends on the cognitive load of the gate-decisions. In our practice, three pods in parallel is comfortable. Five pods is the upper bound before I start losing thread. The economic implications, working backwards: one pod produces output broadly equivalent to a fifteen-person engineering team. Three pods is forty-five-person team. Five pods is seventy-five-person team. The constraint, at every stage, is not the agents — they will work as long as you keep paying the subscription — but the founder's capacity to hold the high-level objective in working memory across pods.
This is, on inspection, a kind of company that did not exist when I started writing this series. A four-or-five-person founding team plus a pod-per-feature plus a Coordinator-per-pod produces, in three weeks, what historically took a fifty-to-hundred-person company a quarter. The team-size compression is, by any historical measure, an order of magnitude. I have, repeatedly, the experience of catching myself describing what we shipped this week and feeling vaguely embarrassed about it. The work is real. The cost is small. The number of human hours involved is, in the conventional sense, absurd.
Against the flat model
There is an alternative organisational pattern emerging in the same window, and I want to address it directly because I think it is wrong.
Garry Tan, the YC president, has been writing about and prototyping what he calls `gstack` — a flat configuration of AI agents working as peers, without a coordinating agent above them. Each agent has its own role; they communicate with each other directly; the human user interacts with all of them in turn. There is no hierarchy. There is no Coordinator. The flat structure mirrors the flat structure of an early-stage startup team, by analogy.
I have a great deal of respect for Garry Tan and for the agentic-engineering writing coming out of YC. I think `gstack`, on inspection, does not scale, and that the flat-team analogy is the wrong one.
It does not scale because communication overhead in a flat group of agents grows quadratically. Two agents, one channel. Three agents, three channels. Five agents, ten. Ten agents, forty-five. Each channel is a potential source of inconsistency, of context loss, of the agents disagreeing about what was decided in some other channel. A flat group of five agents can sometimes coordinate well; a flat group of ten cannot, because no agent has the cognitive bandwidth to track every other agent's state. The flat-team pattern hits a wall at roughly five agents, and the wall is structural, not implementational.
It does not scale because the human at the top has no single point of contact. In a flat team of six agents, the founder has to talk to six agents. Each conversation requires context-setting. Each conversation produces decisions that may or may not propagate to the other five agents. The human becomes — as I did in the brief-shuttling story above — the protocol layer, the message queue, the only entity holding the joined state. The setup undoes the productivity gain that brought the agents in.
It does not scale because the model breaks under feature parallelism. A flat team of six agents, working on one feature, is a different organisational shape from a flat team of six agents working on three features simultaneously. The flat model has no way to encapsulate which feature an agent is currently on. The Coordinator pattern does — it is precisely the encapsulation boundary that lets you run multiple pods in parallel.
The flat-team analogy is wrong because flat human teams, in practice, only work at very small scale — three or four people, where everyone can hold every conversation in their head. Any human company that grew past about fifteen people invented a coordinator role — a CEO, a chief of staff, a project manager — because the alternative was paralysis. The same logic applies, with even sharper force, to teams of agents. The agents do not have the social bandwidth to coordinate themselves. They need the protocol layer, and the protocol layer is an agent.
To be clear about the disagreement: Tan is not wrong to be exploring the flat configuration. Early-stage agent organisations do work flat, in the same way early-stage human start-ups do. What I am claiming is that the flat configuration is a transient state, not a destination. The destination, the moment you try to scale past one founder running one product, is hierarchical. The Coordinator is the role the hierarchy is built around.
Addy Osmani has written about the orchestrator versus conductor distinction in his agent-orchestra essay; the Coordinator role described here is closer to a conductor than to either of those alternatives. The Coordinator is not setting the music. It is keeping the agents in time with each other.
What the human does
The human, in this configuration, sits one layer above the Coordinator. The role is different from anything I have done in twenty years of founding companies.
The human writes the concept for each feature — the paragraph plus screenshot I described in the brief loop article. The concept goes to the Coordinator, not to Claude directly. The Coordinator then runs the pipeline.
The human reviews the locked brief at G1, the locked work scope at G2, and the release notes at G3 for each feature. Three gates per feature, perhaps five to fifteen minutes each. Fifteen to forty-five minutes of human time per feature in total.
The human arbitrates irreducible cross-pod conflicts. When pod A is working on a feature that conflicts with pod B's feature, the two Coordinators surface the conflict to the human. The human reads both briefs, makes a call, and the pods proceed. Maybe one conflict a week per active pod, in practice.
The human sets strategic priority across pods. Which features to fund. Which pods to spawn. Which to wind down when a feature ships. This is the role most analogous to a traditional CEO's job, except scaled to interactions per day rather than per quarter.
The human does not talk to Claude. The human does not talk to Codex. The human does not shuttle artefacts. The human does not, in any meaningful sense, write briefs, work scopes, or code. Those activities are now downstream of the pod boundary; they are agent work, run by the Coordinator.
I will say, slightly uncomfortably, that this is also a description of how a founder of a hundred-person company already spends their time. Set strategy, allocate funding, arbitrate cross-functional disagreement, sign off at gates. The shape of the founder's day, in this configuration, is similar to the shape of a Series B founder's day in 2024 — except the head count under them is not a hundred people. It is a Coordinator per pod, with three to ten pods. The work happening underneath the founder is, in terms of output, identical. The number of humans involved is one.
This is the part of the series I find most uncomfortable to write. I do not, on most days, fully love the conclusion. The hundred-person company I would have built five years ago was, among other things, a place where a hundred people had meaningful work. The four-or-five-person company I am building now is not that. It is something else, and I do not yet have a clean account of what.
Where the pattern fails
The Coordinator pattern is not a magic structure. There are three failure modes I have hit, all of them recoverable but worth flagging if you are about to run one yourself.
The Coordinator hallucinates state. Occasionally a Coordinator will report that the brief loop has converged when it has not, usually because it has lost track of which cycle was the latest substantive review. The fix is to have the Coordinator emit explicit cycle counts and convergence claims in writing — "cycle 3 complete, brief locked" — so the human can spot-check the count against the artefact trail before signing off at G1. Maybe one in twenty briefs needs this catch.
Pod boundaries blur. When two pods are working on adjacent features that touch the same code or database, the two Coordinators may, given the chance, start instructing the same downstream agents in conflicting ways. The fix is hard boundaries: each pod gets its own working branch, its own brief file, its own work-scope file, and the Coordinators are explicitly instructed not to touch artefacts from other pods. Cross-pod handoff happens at the human level, not the agent level.
The founder cannot decompose work into pod-sized chunks. This is the failure mode that breaks small founders most often, in my observation. Not every problem is pod-shaped. Some features genuinely span multiple subsystems, or have such tight coupling that splitting them across two pods produces more coordination overhead than savings. The fix is judgment: if the cross-pod handoff cost exceeds the parallelism benefit, run the feature in a single pod even if it takes longer. The temptation to spawn more pods because pods feel productive should be resisted.
In all three failure modes, the human is doing thinking the Coordinator cannot. The role of the founder, in this configuration, is not less important. It is narrower, higher-stakes, and less forgiving than the founder role in 2024.
The math, briefly
One pod produces output roughly equivalent to a fifteen-person engineering team, working at conventional pace, over the same window. Three pods is forty-five-person team. Five pods is seventy-five. Ten pods, theoretically, is one hundred and fifty.
The constraint, in practice, is not the number of pods you can spin up — it is the cognitive load of the gate-decisions at the top. Each pod produces gate decisions at roughly the rate of one per day during active feature work. Three pods is three gate decisions per day. Five is five. At ten pods, you are arbitrating ten gate decisions per day plus cross-pod conflicts, and the founder's working day is full again — but the throughput is the equivalent of a hundred-and-fifty-person engineering organisation.
The cost is, by conventional measures, absurd. One pod is roughly $340 per month of AI subscriptions ($120 Claude + $220 ChatGPT). Ten pods is $3,400 per month. The equivalent hundred-and-fifty-person engineering organisation costs, fully loaded, roughly $40 million per year. The cost ratio is about one-thousandth of one percent. I do not believe these numbers, on most days, even though I have generated them from the receipts. They will, I expect, get worse — by which I mean better — as model pricing falls and Coordinator competence grows.
Closing
The Coordinator is a third LLM that orchestrates a pod of specialised agents — typically Claude as PM, Codex as Dev, with optional research and QA agents — so the human founder manages agents at the pod-level, not the artefact-level. The pod is the unit of work. The Coordinator is the unit of supervision. Multiple pods run in parallel, each with its own Coordinator. The human, sitting above the Coordinators, is the only human in the structure.
The alternative — the flat virtual team, gstack-style — works at very small scale and stops scaling at roughly five agents. The reason is communication overhead, which grows quadratically in a flat configuration and linearly in a hierarchical one. Every human company that scaled past about fifteen people invented a coordinator role for the same reason. Agent companies will do the same, faster.
The economic implications are not subtle. One pod is fifteen-person team output. Ten pods is hundred-and-fifty-person organisation output, run by one human, for about $3,400 a month. The constraint at every level is the founder's cognitive bandwidth, not the agents.
The next piece in this series — The 90/10 Pattern: A Named Cognitive Failure Mode of Supervising AI Agents — covers what happens to that cognitive bandwidth when the founder is the only human in a hundred-and-fifty-person-output organisation. The Coordinator pattern unlocks the scale. The 90/10 pattern is the thing that breaks the founder running it.
Until then: stop trying to be the protocol between your AI agents. Hire — which is to say, prompt — a Coordinator. Let the Coordinator run the pipeline. You run the Coordinator. Build the org chart. Then build the next pod, and the next, and the next.
Phillip Gales is the founder of [FishDog](https://fish.dog), a synthetic market research platform. This is the fifth in a six-part series on building software with AI agents. Previous pieces — Two AI Agents Are Better Than One: Why I Stopped Trying to QA Codex Myself, Anatomy of an AI-Built Product: 21 Days, 40 Hours of My Time, 128,506 Lines of Code, Product Unit Tests: A Missing Layer of QA in the Age of AI Engineers, and The Product Brief Loop: How Claude and Codex Write Better Specs Than I Can — argued the architectural case for two-agent peer review, walked a real product build through its eight stages, named the missing layer of QA for AI-built software, and detailed the bidirectional discipline that makes AI-built specs work. The next piece — The 90/10 Pattern: A Named Cognitive Failure Mode of Supervising AI Agents — names the burst-load burnout pattern that emerges when one human supervises a multi-pod agent organisation.