
By Phillip Gales · May 2026
The brief I did not write
In late February, I handed Claude a one-paragraph product concept and got back, three hours later, a 22-page product brief I disagreed with on three significant points. By the end of the next day, the brief was 31 pages, the three points had become twelve sub-decisions, and I no longer disagreed with any of them. I had not typed a single word of the brief myself.
What I had done, instead, was open the brief in one window, open another agent in a second window, and ask the second agent to tell me what was wrong with the first agent's brief. The second agent — Codex, living inside the codebase, with full visibility on what the brief was implicitly assuming — came back with seven observations. Four were minor copy nits. Two were genuinely useful clarifications. One was a load-bearing structural mistake in the brief that I would have shipped to the engineering team without noticing.
I sent the seven observations back to Claude. Claude read its own brief, read the critique, and produced a revised brief. The seven observations had become twelve sub-decisions, each one explicitly resolved. I sent the revised brief back to Codex. Codex flagged two new things — one minor, one a remaining ambiguity. Claude revised again. The third pass returned with no new findings. The brief locked.
This is, in mid-2026, the discipline that has become the most consequential change in our engineering process. The loop between two frontier LLMs, alternating between authorship and critique, until convergence. The brief is co-authored by Claude and Codex. So is the dev work scope. My role is to set the original concept, arbitrate the rare irreducible disagreement, and lock the artefacts at the gates. Most of the writing happens, in alternation, between two agents that read each other's work, disagree in specific ways, and converge through structured iteration.
This article is about how that loop works. The mechanic, the iteration counts, the convergence criteria, the prompts. The piece is more practitioner-grade than the earlier pieces in this series. If you want the epistemic case for two-agent peer review, that is the first article. If you want the case-study evidence, the second. This piece is the manual.
Why one-direction reviews break
There is an existing literature on what people now call spec-driven development. Addy Osmani has written usefully about the orchestrator-versus-conductor distinction, and his "how to write a good spec for AI agents" covers the human-written spec. Hamel Husain's `claude-review-loop` plugin automates a version of the brief handshake. GitHub's Spec-Kit and Martin Fowler's foundational writing on SDD provide the templates. AGENTS.md, the September 2025 multi-vendor standard, gives us a common file format for agent-readable project specs.
What is missing, in almost all of the existing literature, is the second direction.
The conventional shape of spec-driven development is human-writes-spec, AI-implements-spec. Or, in the more agentic 2026 version, AI-writes-spec, human-reviews-spec. Either way: one author, one reviewer, one direction. The human is in the loop at the spec stage and out of it at the implementation stage.
This works, on smaller projects, when the spec author and the spec reviewer agree on what good looks like. It works less well, on serious projects, when they don't. And it stops working entirely when the spec author is an LLM operating at the limit of its capability, because the human reviewer can no longer reliably evaluate whether the spec is good. Whichever direction you are running the one-direction review, you have the bottleneck I described in the first piece in this series: the human either becomes the speed limit or becomes a rubber stamp.
The answer, for the reasons argued in that first piece, is a second frontier LLM with systematically different blind spots. The answer for briefs specifically is the bidirectional handshake. Not one agent writes, one agent reviews. Two agents alternate. The brief loop runs as agent-write, agent-critique, agent-revise, agent-re-critique, until convergence. The work scope loop reverses the polarity. The human is in the loop only at the gates: at the original concept, at the locked brief, at the locked work scope, and at the rare irreducible disagreement that the agents themselves cannot resolve from context.
This is the discipline this article describes.
The mechanic, in detail
The loop has two phases. They are different in important ways.
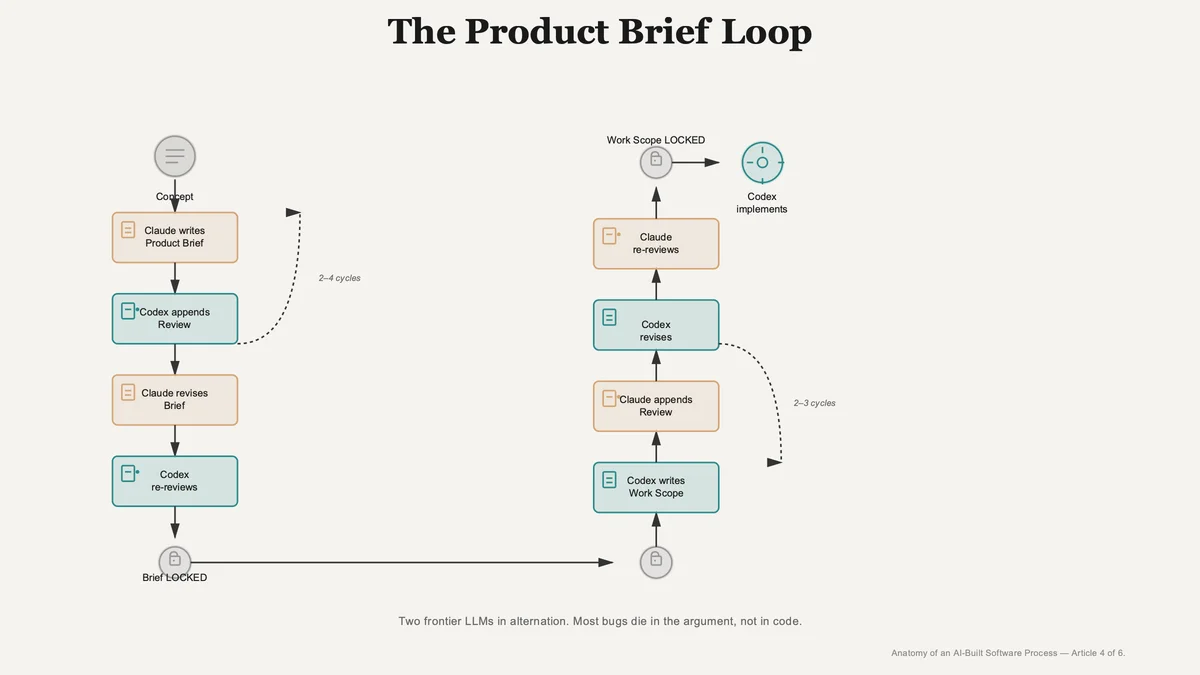
Phase 1 — the brief loop. Claude is the author. Codex is the reviewer.
I start with a concept. Sometimes this is a paragraph; sometimes it is a UI sketch on a whiteboard photographed and dropped into the conversation; sometimes it is a screenshot of the current product with a complaint about it. I hand the concept to Claude with a one-sentence instruction: write a product brief for this. Cover the user problem, the proposed solution, the acceptance criteria, and the edge cases. The reader is a developer.
Claude returns a brief. The first draft is, in our pipeline, typically 8-15 pages of markdown. It is structurally correct most of the time. It will, on close reading, contain at least one assumption I want to challenge.
Rather than challenge it myself, I hand the brief to Codex with explicit instructions. Read this brief. Append your review notes to the bottom of the same file, in a section headed "Codex review". Do not edit the brief itself. Do not rewrite it. Append. Identify: structural mistakes, implementation issues you can foresee, places where the brief contradicts something already in the codebase, edge cases the brief has missed, and any places where the brief is internally inconsistent or ambiguous.
Codex returns the brief with an appended review section. The review is, in our pipeline, typically one to three pages. I read it. I almost always learn something. Codex catches things Claude missed because Codex sees the codebase that Claude does not. The brief assumes a database schema that has changed; Codex notices. The brief specifies a UI element that already exists with subtly different behaviour; Codex notices. The brief defines an edge case the existing system already handles; Codex notices.
I hand the annotated brief back to Claude with another explicit instruction. Read your brief, read Codex's review at the bottom, and produce a revised brief. Resolve each of Codex's observations explicitly: either incorporate it, or document why you have chosen not to. Do not delete the Codex review; leave it visible below the revised brief for the next reviewer.
Claude returns the revised brief. The Codex review is still appended at the bottom. Below the Codex review, Claude has added a section called "Claude response", in which each of Codex's observations is addressed. Most are incorporated. One or two might be rejected with reasoning.
The annotated artefact now has three layers, top to bottom: revised brief, Codex's first review, Claude's response to Codex's review. The document is growing. The trail is visible.
Back to Codex for the second pass. Codex reads the revised brief, reads the response, and appends a new section: "Codex review, second pass". The reviews tend to get shorter on each cycle. Codex flags any remaining ambiguities and, where Claude has rejected an earlier observation, says whether the rejection is acceptable.
Back to Claude. Third revision. Codex review three. Sometimes a fourth. Almost never a fifth.
The brief locks when both agents independently agree, at the end of a cycle, that the brief is ready for a developer to implement against. I will return to that convergence criterion shortly.
Phase 2 — the work scope loop. The polarity reverses. Codex is the author. Claude is the reviewer.
The locked brief goes to Codex with a new instruction: write a developer work scope for the brief above. Cover the files to change, the test plan, the rollout plan, the rollback plan, and the locked architectural decisions with their reasoning.
Codex returns the work scope. Typically five to ten pages, more concrete than the brief, written in the language of the implementation.
Claude reviews. Read the brief above and the work scope below. Append a review section. Identify: places where the work scope drifts from the brief, structural decisions in the work scope that conflict with the user need stated in the brief, missing test cases, missing rollback plans, and any implementation choices that close off important future options.
Same cycle. Codex revises, Claude re-reviews. Typically two or three cycles, slightly shorter than the brief loop. The work scope tends to converge faster because the brief has already done most of the architectural thinking.
The work scope locks when both agents agree it is ready. The locked work scope is the input to implementation. Codex builds against it. The brief becomes the source of truth for product QA. The architectural decisions, all twelve or whatever the count is for this particular feature, are referenced by both downstream artefacts.
This is the entire loop. The whole thing typically takes between three and six hours of wall-clock time per feature, with maybe 30-45 minutes of my attention.
Convergence criteria
The hardest question, in my experience, is when to stop iterating. I have arrived at three heuristics.
Heuristic one: ask the agents. Before declaring a brief or work scope locked, I ask the relevant agent — usually the one that wrote the latest revision — a deceptively simple question: Is this brief high enough quality that a developer can implement it accurately, cleanly, and quickly? If not, what specifically is missing or weak?
Roughly a third of the time, the agent says no. It then surfaces what is missing. I have not yet stopped being surprised by how good agents are at noticing the weaknesses in their own output, when explicitly asked. I want to be careful with this claim, because "ask the agent if its work is good" sounds like the kind of advice that should not work and very often does not. The reason it works in this specific context is that the agent has the brief in its context window, has the previous reviews in its context window, and is being asked a narrow procedural question rather than an open-ended one. It is not introspecting on its own quality in some general sense. It is comparing the latest revision against the prior reviews and answering a specific question about implementation-readiness.
Heuristic two: count diminishing returns. Each review cycle should produce fewer, smaller findings than the previous one. The first Codex review is typically 5-15 substantive observations. The second pass is typically two to five. The third pass should be zero to two, mostly minor copy or ambiguity flags. If a cycle returns more findings than the previous one, something has gone wrong — usually the revision introduced new problems while solving old ones. Roll back to the previous revision and try a different approach.
Heuristic three: agreement. The brief locks when Codex's review returns no substantive findings, AND when Claude — having read its own brief one more time — agrees the brief is ready. The double agreement is the lock condition. If either agent flags anything substantive on a final pass, another cycle is needed. In practice this lands at three or four cycles for briefs and two or three for work scopes.
There is a fourth heuristic, less reliable, that I include for completeness: count the locked decisions. A serious brief, on a non-trivial feature, will end up with somewhere between 8 and 20 explicitly locked architectural decisions. Each decision is named, motivated by a user need from the brief, traded off against alternatives that were considered and rejected, and referenced from the work scope. If your brief locks with fewer than 8 explicit decisions, you have probably under-specified. If it locks with more than 20, the brief is doing the work scope's job and the boundary has dissolved.
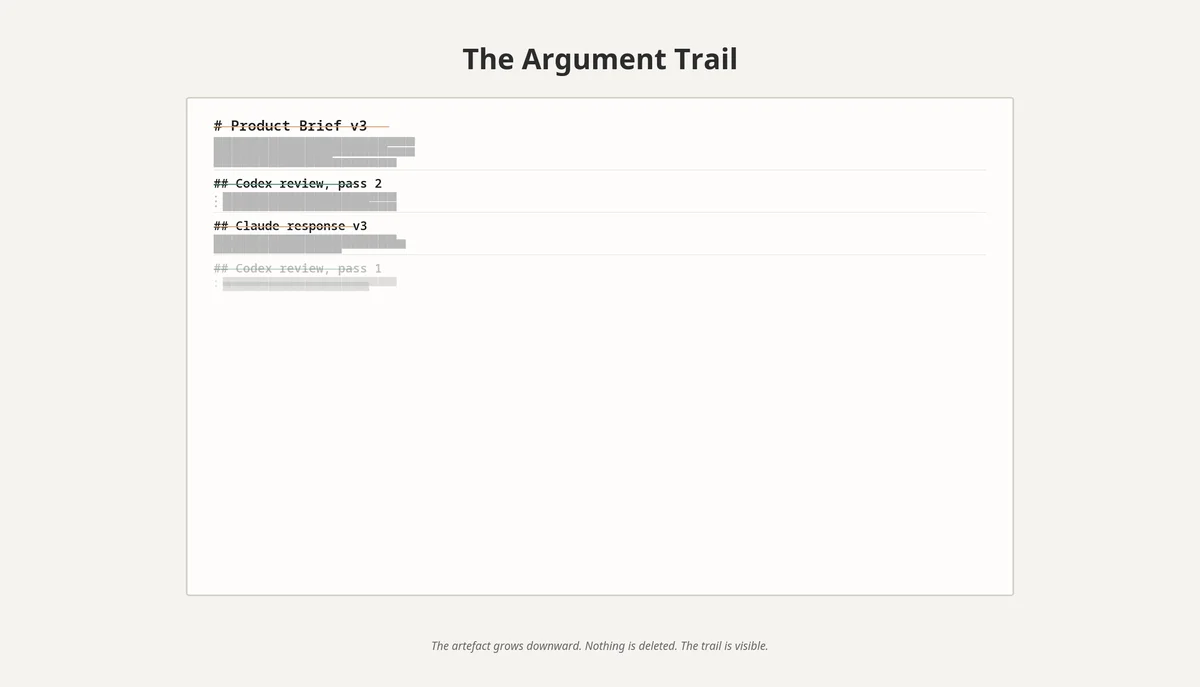
The appended structure matters. Each agent's review and each author's response is preserved in the same file, in chronological order, with section headers. The artefact grows downward. By the time the brief locks, the file is a record of the entire argument — every observation, every response, every decision. This has two compounding benefits. The first is that you can audit the brief afterwards: every locked decision has a paper trail. The second is that you can hand the file to a third party — a new team member, an LLM with no context, your future self — and they can reconstruct why the brief looks the way it does.
I have come to regard the appended structure as load-bearing. The agents are noticeably less effective if you ask them to rewrite rather than append. A rewrite throws away the argument structure; an append preserves it. The reviewer agent reads the previous reviews and can avoid raising observations that have already been addressed. The author agent can see the cumulative state of the argument and judge when convergence has actually been reached.
The skill files
The loop runs on prompts. I keep them in version control. They are stable; they evolve only when an experiment shows a better wording.
The brief-author prompt for Claude is, in essence, this:
You are a senior product manager writing a product brief for a developer. The reader is technically literate and will use this brief to implement the feature. Cover, in this order: the user problem, the proposed solution, the acceptance criteria, the edge cases, and the explicit architectural decisions you have made and their trade-offs. Be concrete. Use specific user vignettes where they clarify the requirement. Use markdown. Append your brief at the top of any existing review notes; do not delete the review notes; respond to them in a section called "Claude response" beneath the previous reviewer's notes.
The brief-reviewer prompt for Codex is, in essence, this:
You are a senior developer reviewing a product brief written by a colleague. You have full visibility on the existing codebase. Read the brief. Append your review at the bottom of the file, in a section headed "Codex review". Identify: structural mistakes, implementation issues you can foresee, places where the brief contradicts the current codebase, edge cases the brief has missed, internal inconsistencies or ambiguities. Be specific. Reference file paths and existing functions where relevant. Do not rewrite the brief; append your review.
The work-scope-author prompt for Codex inverts the polarity:
You are a senior developer writing a work scope for a feature that has been specified in the locked brief above. Cover, in this order: the file-level change list, the test plan, the rollout plan, the rollback plan, and the locked architectural decisions with their reasoning. Reference specific files, functions, database tables, and migrations where relevant. Use markdown. Append your work scope below the locked brief; do not delete or rewrite the brief.
The work-scope-reviewer prompt for Claude:
You are a senior product manager reviewing a work scope written by the dev team. Read the brief above and the work scope below. Append a review section. Identify: places where the work scope drifts from the brief, structural decisions in the work scope that conflict with the user need stated in the brief, missing test cases, missing rollback plans, implementation choices that close off important future options.
These four prompts are the entire instruction set for the loop. Every other instruction is given inline in the conversation, or follows from the appended review's content. The stability of the role assignment is the thing that makes the loop work. Claude knows it is the PM. Codex knows it is the dev. Neither agent is asked to do the other's job. The cross-review is precisely the role that benefits from the other lens.
The self-assessment heuristic — is this high enough quality? — is asked outside the file, in a separate conversation, of whichever agent produced the latest revision. The answer is recorded in the file under a section called "Self-assessment". I have included this in our pipeline for about three months. It catches roughly a third of issues that the two-agent review missed. It costs about one paragraph of agent time per cycle. It is, on cost-per-bug-caught, the highest-leverage gate in the whole pipeline.
Stress-testing the brief with synthetic users
The loop, as described above, runs between two agents looking at the brief from internal vantage points — Claude understands the product strategy, Codex understands the codebase. Neither has the lens of the actual user the feature is meant to serve. Until very recently, that gap was filled by the human PM mentally simulating the user as they wrote the brief. That mental simulation does not, on inspection, scale either.
The natural extension is to stress-test the locked brief against synthetic representatives of the target user. We do this in our pipeline by handing the brief to FishDog's synthetic-persona pool — a panel of, say, fifteen hedge-fund-analyst personas, each with their own background, current frustrations, and patience thresholds. The personas read the brief in user-perspective form (a one-page narrative extracted from the locked brief) and answer four questions: Would this feature solve a problem I have? Would the proposed UX make sense to me? Are there obvious edge cases the brief has missed from a user's standpoint? What would you find disappointing if this shipped?
The reports come back from fifteen agents in roughly five minutes. The signal is variable. Sometimes all fifteen personas agree the brief is good. Sometimes three or four flag the same underspecified detail and the brief opens for a fourth iteration. Occasionally a single persona surfaces a user-perspective concern that none of the others share — and, on inspection, that lone voice turns out to be the load-bearing problem with the brief.
This is, in effect, a third reviewer added to the loop. Unlike Claude and Codex, the user personas review from the lens of the human the brief is meant to serve. In our pipeline, the synthetic-user pass happens between the brief locking (Phase 1 complete) and the work scope authoring (Phase 2 begins). The locked brief is the brief that has passed both the bidirectional agent loop and the synthetic-user pass. The result is a brief optimised not only for engineering plausibility, but for user resonance.
Where the loop fails
The loop is not infallible. There are three failure modes I have seen.
The loop oscillates. Occasionally, Codex's review will surface an observation that Claude addresses, then Codex's next review will surface a different observation that Claude addresses, then Codex's third review will return to the original observation and disagree with how it was addressed. The brief is going in circles. This happens when there is a genuine architectural ambiguity neither agent can resolve from context. The fix is to escalate: I read the disagreement and arbitrate. Maybe one in eight features needs this; the disagreement is almost always something I needed to think about anyway.
Both agents agree on something wrong. This is rarer than I expected. The orthogonality of the two models' training data, post-training objectives, and deployment contexts means they tend to fail in different ways. But occasionally both will miss the same thing — usually a piece of corporate context the agents do not have. The fix is to read the locked brief one more time before signing off. The human role is narrower than it was; it is not zero.
The brief is too abstract. If the concept I hand Claude is genuinely vague — "build a thing that lets users do market research faster" — the loop will converge on a beautiful, structurally-correct brief that solves a problem nobody asked for. The fix is upstream: refine the concept until it has at least one concrete user vignette. The agents can write the brief from the vignette; they cannot, reliably, invent the vignette.
In all three failure modes, the human is doing thinking the agents cannot. That is, increasingly, the only thinking the human is doing.
What this changes
Three things, briefly.
It changes what a product brief is. The brief is no longer a one-author document. It is a co-authored artefact, with a visible argument trail and explicit locked decisions. The author of record is not a single person; it is the loop. This shifts how briefs are read by the engineering team: not as one PM's opinion, but as the output of a structured argument.
It changes what writing a brief means as a skill. The discipline that used to matter — clear prose, structured thinking, anticipation of edge cases — still matters, but is increasingly done by Claude. The new discipline is steering the loop: writing concepts concrete enough to be useful, choosing when to escalate, recognising when convergence has been reached, and lock-gating the artefacts at the right moments. This is, on inspection, a more senior skill than the one it replaces.
It changes the brief's relationship to the rest of the pipeline. Because the brief flows through to the work scope and through to product unit tests, the brief is now the foundational artefact of the entire feature. Get the brief right and the rest of the pipeline tends to fall into place. Get it wrong and every downstream artefact propagates the error. The first piece in this series argued for two-agent peer review on epistemic grounds. The product unit test layer, described in the previous piece, tests the experience against the brief. The brief sits at the centre of the pipeline. The brief loop is what makes it trustworthy.
Closing
The Product Brief Loop is a bidirectional structured argument between two frontier LLMs. Phase 1: Claude writes a brief, Codex appends a review, Claude revises, Codex re-reviews, until convergence at two to four cycles. Phase 2: polarity reverses, Codex writes a work scope, Claude appends a review, Codex revises, Claude re-reviews, until convergence at two to three cycles.
Convergence is measured by three heuristics: the agent's own self-assessment ("is this high enough quality?"), diminishing returns on each cycle, and the double-agreement lock at the end. The appended-not-rewritten discipline preserves the argument trail. The four prompts that drive the loop fit on a single page.
The brief is no longer one person's document. It is the co-authored output of a loop that converges, predictably, on something better than either agent — or any individual human — produces alone. The human, in this loop, does three things: writes the concept, arbitrates the rare irreducible disagreement, and locks the artefacts at the gates. Everything else, by volume, is written by Claude and Codex, in alternation, in markdown, in the same file.
The next piece in this series — The Coordinator: Why Founders Won't Manage People, They'll Manage Agents — covers what happens when the loop becomes the primary unit of organisational work. If the brief loop is the discipline, the Coordinator is the role that emerges around it.
Until then: stop trying to write briefs alone. Stop asking a single LLM to write a brief alone. Put two frontier LLMs in alternation, in markdown, in the same file, with explicit author and reviewer roles. Stop iterating when both agree the brief is ready. Lock it. Hand it to the implementation. Most of the bugs you would have shipped have already died in the argument.
Phillip Gales is the founder of [FishDog](https://fish.dog), a synthetic market research platform. This is the fourth in a six-part series on building software with AI agents. Previous pieces — Two AI Agents Are Better Than One: Why I Stopped Trying to QA Codex Myself, Anatomy of an AI-Built Product: 21 Days, 40 Hours of My Time, 128,506 Lines of Code, and Product Unit Tests: A Missing Layer of QA in the Age of AI Engineers — argued the architectural case for two-agent peer review, walked a real product build through its eight stages, and named the missing layer of QA for AI-built software. The next piece — The Coordinator: Why Founders Won't Manage People, They'll Manage Agents — covers the organisational shape that emerges around the brief loop.