

By Phillip Gales · May 2026
The bug that passed every test
Sometime in early April, I shipped a feature that passed every test we had and was, on inspection, broken.
The function under test returned what the test expected. The endpoint returned the right shape of JSON. The integration test ran the new code path without erroring. The smoke test stayed green. By every measure available to the engineering pipeline, the feature shipped clean.
The user couldn't use it.
The button was on the wrong side of the page. The success message used phrasing the product brief had specifically asked us to avoid. The number it returned was correct as a number and wrong as a presentation — three significant figures where two would have read better, rounded down where the customer expects rounded up. None of those things broke the tests, because none of those things were tests. They were product-level questions the test stack had no way to ask.
I want to be careful with this anecdote, because I do not want it heard as a complaint about my engineering team. The bug was in the brief-to-code translation, not in the code. The code did what the code was asked to do. What I did not have, and what I am increasingly convinced no engineering team has yet, was a layer of testing that asked: does the experience that ships match the product brief that was written. That, until recently, was answered by a human in QA clicking through the product and complaining when something looked wrong. The reason this has stopped working is the same reason most of what I am writing about in this series has stopped working: agents now write the code faster than humans can manually walk through what they have built.
This article is about the test layer that has gone missing. About what the new layer is, what it should be called, and how to build it. About a category of testing I am going to call product unit tests, because nothing in the existing vocabulary fits, and because naming the thing is the first step to taking it seriously.
The shape of the existing test stack
A serious engineering team in 2026 has, in roughly increasing order of expense and decreasing order of execution speed, the following test layers:
Unit tests — Does this function return what the developer expects?
Integration tests — Do these two modules cooperate the way the developer expects?
API tests — Does this endpoint return the right shape of data?
End-to-end tests — Can a synthetic user walk through this flow without the system breaking?
Smoke tests — Does the deployed system stay up under representative load?
Manual user acceptance testing — Does a real human, walking through the product, find it acceptable?
Each layer answers a different question and catches a different class of bug. Their union is, broadly, what we mean when we say a software product is tested. None of them, on inspection, answers the question that matters most to product correctness: does the experience the user is about to have match the experience the brief said they should have.
This is not a new observation. Every engineering team I have ever worked with has known, in the abstract, that the test stack does not catch product-level mismatches. The standard answer has been manual QA. Someone — sometimes a dedicated QA engineer, sometimes the PM, sometimes a junior who drew the short straw — sits down with the brief, opens the product, and walks the flow. They click the button. They read the message. They check the number. If anything in the experience disagrees with the brief, they file a bug. The cycle takes, in a typical mid-sized organisation, between half a day and three days per feature.
That answer worked when human developers wrote code at human speed. It works less well when humans write the code with the help of agents, because the agents write faster than the human QA can read. It stops working entirely when the agents write the code, because the throughput gap between authorship and verification widens by an order of magnitude. The previous piece in this series walked one such build: 128,506 lines of production code in 21 days, with 40 hours of human attention. A team shipping ten features a day cannot have ten manual QA passes a day. Either the manual QA becomes a rubber stamp, or it becomes the bottleneck. In our pipeline, both happened, in alternation, for about a month, before I gave up and built the missing layer.
A definition
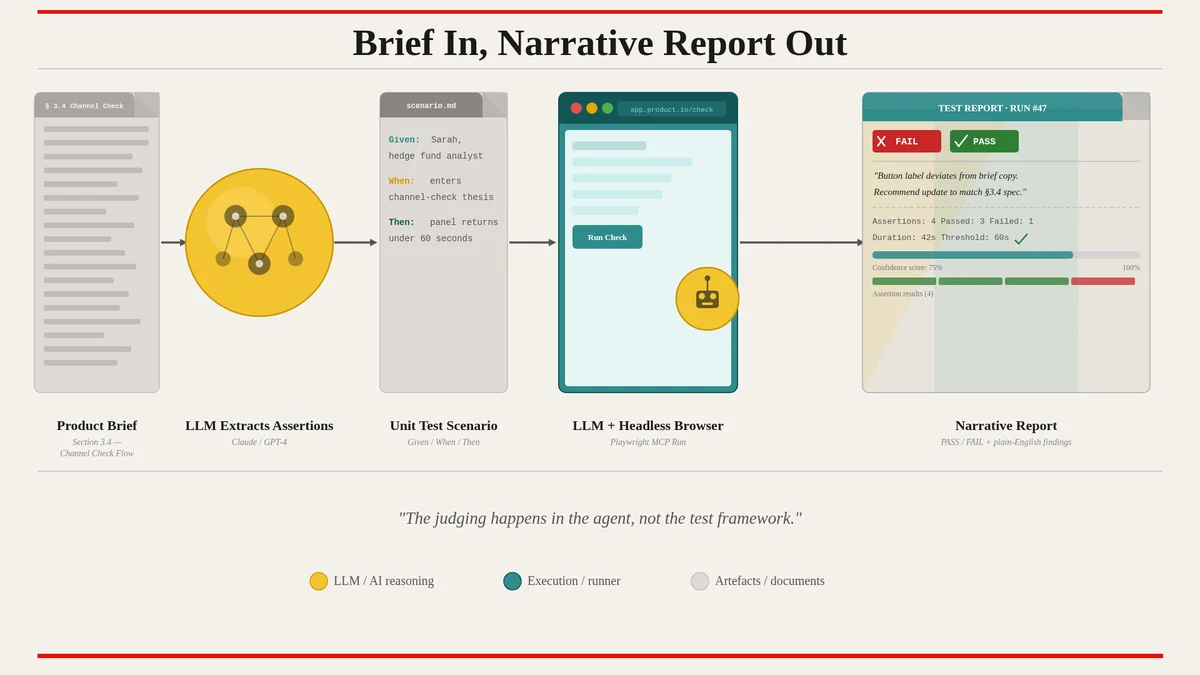
A product unit test is an executable assertion, written from the user's perspective, run by an LLM driving a headless browser, evaluated against the product brief.
That is the entire definition. The four phrases each carry weight.
Executable assertion. Not a checklist a human reads. Not a Jira ticket a tester picks up. An assertion that runs, on every change, in the continuous integration pipeline, and produces a pass or a fail. This is the property that lets it scale at agent speed: if it runs, it can run a hundred times an hour without complaint.
From the user's perspective. Not "does function X return Y" — a developer-perspective question. The product unit test asks "if I log in as Sarah, click the channel-check tab, and type a thesis about supply chain margins, does the system return a research group that looks like what Sarah was hoping for." It speaks in the language of the brief, not the language of the function signature.
Run by an LLM driving a headless browser. The mechanism. This is what was, until very recently, not possible. With the release of Playwright MCP and the broader Model Context Protocol substrate in late 2025, an LLM can now drive a real browser session with the same affordances a human user has — clicks, scrolls, form fills, screenshot reads. It can see the page. It can interpret what it sees. It can compare what it sees to what the brief said it should see.
Evaluated against the product brief. The judge. The LLM does not check whether the button is at coordinate (412, 218). It checks whether the button is where the brief said it should be, in a presentation that matches what the brief described. The evaluation is semantic, not pixel-exact. This is the property that lets product unit tests survive ordinary visual reflow without false-positiving.
Put together, the four phrases describe a category of test that did not exist three years ago, could not have existed in 2023, and is, in mid-2026, becoming a tractable engineering practice. I have not seen anyone else name it. Someone is about to. I think it is worth naming carefully, because the name will shape the discipline.
How it actually runs
The architecture is, mercifully, simple. Each product unit test is a small markdown file that pairs a brief excerpt with a test scenario. Roughly:
Brief reference: Section 3.4, "Channel Check Creation Flow" Scenario: As a hedge fund analyst, I should be able to create a channel-check research group by entering a free-text description of the group I want to talk to. The system should return a recruited panel within 60 seconds. The interface should show the panel composition while it recruits, not after. Acceptance: A live progress display showing partial results, not a spinner. Final result returns within 60 seconds. The presented panel is recognisable as what the user asked for.
The test runner, at every change, asks an LLM (in our pipeline, Claude) to:
Log in as a test user via the headless browser.
Navigate to the feature described in the brief reference.
Carry out the scenario as a user would.
Observe what happens.
Compare the observation to the acceptance criteria.
Report pass or fail, with a short narrative explanation.
The narrative explanation is the part nobody who has worked with traditional test frameworks expects. A product unit test that fails does not say AssertionError: expected "Submit", got "Send". It says "The button label reads Send rather than Submit, which contradicts the brief's specification in Section 3.4. The user would still understand the intent, but the wording deviates from the agreed copy. Recommend either updating the brief or updating the UI."
Three properties of this set-up turned out to matter more than I initially expected.
First, the narrative report. A human PM reading a stack of test failures can triage them — "this one is a copy nit, this one is a real bug, this one is a brief that needs updating" — in a way that, before, took a Jira-thread back-and-forth between QA and engineering and product. The LLM's narrative explanation collapses the triage step.
Second, the brief reference. Every product unit test is anchored to a specific section of the brief. When a test fails, the failure has a paper trail: this scenario, from this brief, against this section. The brief becomes, in effect, executable documentation. Updating the brief without updating the tests now produces immediate, automated alerts that the brief and product have desynced.
Third, the regeneration. Product unit tests do not have to be hand-written. The same LLM that writes the brief can generate the test scenarios from it. When the brief is updated, the tests can be regenerated. When the product changes, the tests describe the new expected behaviour. The unit of authorship is the brief; the tests are a derivative, kept consistent by the same workflow that maintains the brief.
This is, on reflection, the property that closes the loop. The brief and the tests are no longer two artefacts maintained by two different people in two different tools. They are one artefact, with a generated derivative, kept in sync by the agent that maintains both. The product unit test layer is not so much a new thing to write as a new way of writing what was already being written.
What it replaces — and what it doesn't
The product unit test does not replace unit tests. Unit tests check that a function does what its author intended, which is a different question from whether the function does what the user needed. Unit tests live closer to the code; product unit tests live closer to the experience. Both are necessary. Neither subsumes the other.
It does not replace integration tests, smoke tests, or API tests. Those layers catch system-level breakage at execution time. They will continue to do that.
It does, in our pipeline, substantially replace the manual user-acceptance-testing pass. The walkthrough that used to take a QA engineer half a day now runs in the background on every commit, in eight minutes, and produces a more useful report than the human pass did. We still do a manual UAT for major releases, because it builds organisational confidence in a way that a passing test suite does not, but it is no longer the workhorse layer. The workhorse layer is the product unit test suite, and the manual UAT is a sanity check.
It does, more interestingly, change what manual QA is for. The job is no longer "click through the product and check the brief." The job is now "design the product unit test suite, review the agent's authorship of test scenarios, and intervene when the test reports surface real disagreements between the brief and the product." This is, on inspection, a substantially more senior job than the one that used to exist. The QA function shifts from a click-through chore to a test-design discipline.
I am not, on most days, sure what to make of this. The PMs and QA engineers in this new structure are doing more interesting work, on harder problems. They are also, on every team I have seen do this, fewer in number. The same restructuring that makes the discipline more interesting makes the team smaller. Both effects are real, and I do not, yet, have a clean account of which one wins.
Why "product unit test"
The name matters. I have tried five.
Acceptance test is the closest existing term. The Agile literature has used "acceptance test" since the early 2000s to describe user-perspective validation. The problem is that "acceptance test" carries a strong implication of human walkthrough, which is exactly what the new layer is not. The agile vocabulary was built for an era in which "user perspective" implied "human reader." That implication no longer holds. The agent is the executor; the human is the test designer.
Behaviour-driven test (from BDD / Cucumber / Gherkin) is the next closest. BDD scenarios are written in user-perspective natural language and are nominally executable. The catch is that BDD scenarios are matched to step definitions via regex, which is brittle, ugly, and required engineers to maintain a parallel tree of brittle code mapping English to function calls. The LLM-driven version skips the step-definition layer entirely. There is no regex. The agent reads the scenario, the agent reads the page, the agent reports the result.
End-to-end test is a closer existing relative. Playwright, Cypress, Selenium — these frameworks already drive headless browsers through user flows. The reason they do not collapse into the product unit test is, again, the evaluation layer. An E2E test ends with an `expect(button).toHaveText('Submit')` style assertion. A product unit test ends with the LLM reading the page against the brief and judging whether the experience matches. The substrate (Playwright) is the same. The judgment layer is different.
Narrative test and scenario test are clean but generic. They do not signal executable. They do not signal the layer in the stack. They do not invite the right comparisons.
Product unit test is the one I have come back to. It inherits from "unit test" the implication of small, focused, executable, deterministic. It inherits from "product" the implication of user-perspective, brief-anchored, experience-evaluated. The name is doing definitional work: each word constrains the other. A unit test that is a product test, not a code test. A product check that is unit-scoped and executable, not a sprawling manual walkthrough. The compound is what is novel.
This is the name I am going to use. I am, for what it is worth, going to use it from here onwards in everything I write about how to build AI-driven engineering pipelines. I would rather we settled on this term than on something else, because the alternative is that someone else coins it under a worse name and the discipline gets harder to talk about. So if you are working on this layer yourself: product unit test. Three words, layered semantics, no obvious rival.
Running them at scale with synthetic personas
There is one further property of this set-up that I want to flag, because it is where FishDog earns its place in the QA layer.
A product unit test, as I have described it, is run from the perspective of a single user — usually a generic test account. The test asks: for this account, doing this thing, does the experience match the brief. This is useful, but it is one perspective.
Real products are used by many kinds of user, with different goals, different mental models, and different patience thresholds. A button that is in the right place for an experienced analyst may be invisible to a first-time visitor. A success message that reads cleanly to a native English speaker may parse oddly to someone whose first language is not English. A pricing display that makes sense to a hedge fund analyst may baffle a private equity analyst whose category-language is subtly different.
The same headless-browser, brief-driven test runner can be pointed at a different persona for each run. The brief stays the same. The acceptance criteria stay the same. What changes is who the user is. Run the product unit test as a synthetic hedge fund junior analyst, then as a private equity associate, then as a healthcare-research analyst, then as a non-native-English-speaking new hire, and you get four reports about whether the experience matches the brief from four different vantage points. The brief did not promise different experiences to different personas. If the personas disagree, the brief is underspecified.
We do this in our pipeline by pointing the test runner at the FishDog synthetic-persona pool. Three hundred thousand agents, each with their own demographic, occupation, and persona, any of which can be drafted as the user-of-record for a given test run. The cost per persona-test is essentially zero. The cost of running a brief against forty representative personas, on every change, is a few minutes of agent time. The result is a coverage of user-perspective bug surface that no manual QA team has ever, in the history of software development, been able to assemble.
I will write more about this in a later piece. For the present article, the point is just this: the product unit test layer scales naturally past one user. The same scaffolding that lets one agent walk one flow lets a hundred agents walk a hundred slightly different versions of that flow. The layer is unit-scoped by name but population-spanning in practice. That is, I think, the property that will make it eventually obvious.
What this changes
Three things, briefly.
It changes the role of the PM. The product brief is no longer a document that gets read and interpreted by a human team. It is a contract against which the product is automatically tested. A brief that does not say what the user should experience precisely enough for an agent to evaluate the experience against it is a brief with a hole in it. The discipline of writing testable briefs — already a real skill — becomes an explicitly engineering-grade skill. The next piece in this series, The Product Brief Loop, covers what writing those briefs looks like in practice.
It changes the role of QA. The job is no longer the manual click-through. The job is the design and curation of the product-unit-test suite. This is harder, more senior, and more leveraged. The teams that figure this out first will be unrecognisable from the teams that did not, on the metrics that matter.
It changes the meaning of ready to ship. A pull request that passes unit, integration, API, smoke, and end-to-end tests is no longer ready to ship. It is ready to be product-unit-tested. The new gate is the brief-against-experience check. Code that passes the engineering tests but fails the product unit tests is, in our pipeline, simply not shipped. That gate is now automated. It runs on every commit. It is, by some measures, the most consequential change in our engineering process this year.
Closing
A product unit test is an executable assertion, written from the user's perspective, run by an LLM driving a headless browser, evaluated against the product brief.
Take that sentence with you. It is the layer of QA that, until very recently, did not exist; that the existing test stack does not catch; that manual QA used to fill at slow human speed; and that no amount of running the existing test layers harder can substitute for. The agents who now write our code do not need more unit tests, more integration tests, or more smoke tests. They need a test layer that asks did you build what the brief said. That is the product unit test.
The next piece in this series — The Product Brief Loop: How Claude and Codex Write Better Specs Than I Can — covers the discipline of writing the briefs against which product unit tests run. The product unit test layer is only as good as the brief it tests against, and the brief is, increasingly, the most important document in the engineering pipeline. We will spend an article on how to write one that survives the new tests.
Until then: stop trying to manually click through what your agents are building faster than you can read. Build the layer that asks the brief-level question, automatically, on every change. Call it a product unit test, please. The name is the start of the discipline.
Phillip Gales is the founder of [FishDog](https://fish.dog), a synthetic market research platform. This is the third in a six-part series on building software with AI agents. Previous pieces — Two AI Agents Are Better Than One: Why I Stopped Trying to QA Codex Myself and Anatomy of an AI-Built Product: 21 Days, 40 Hours of My Time, 128,506 Lines of Code — argued the architectural case for two-agent peer review and walked a real product build through its eight stages. The next piece — The Product Brief Loop: How Claude and Codex Write Better Specs Than I Can — covers the discipline of writing testable briefs.