

Personas now react to video. Upload one clip, point a research panel at it, and each persona answers individually in the same workflow that already supports text, images and PDFs.
The mechanic is the same panel you already use for text questions: pick a research group, drop a video into the attachment area, type the question, submit. One video per question, any number of personas. The capability is gated to FishDog's media and production tiers.
Why we built this
Until this release, the panel saw images and read PDFs. Video was the next obvious modality and the one media-research customers asked for first. Trailers, advertisements, scene-by-scene scripted content and short-form social video do not reduce cleanly to a screenshot or a transcript. They needed to land as video.
What's new
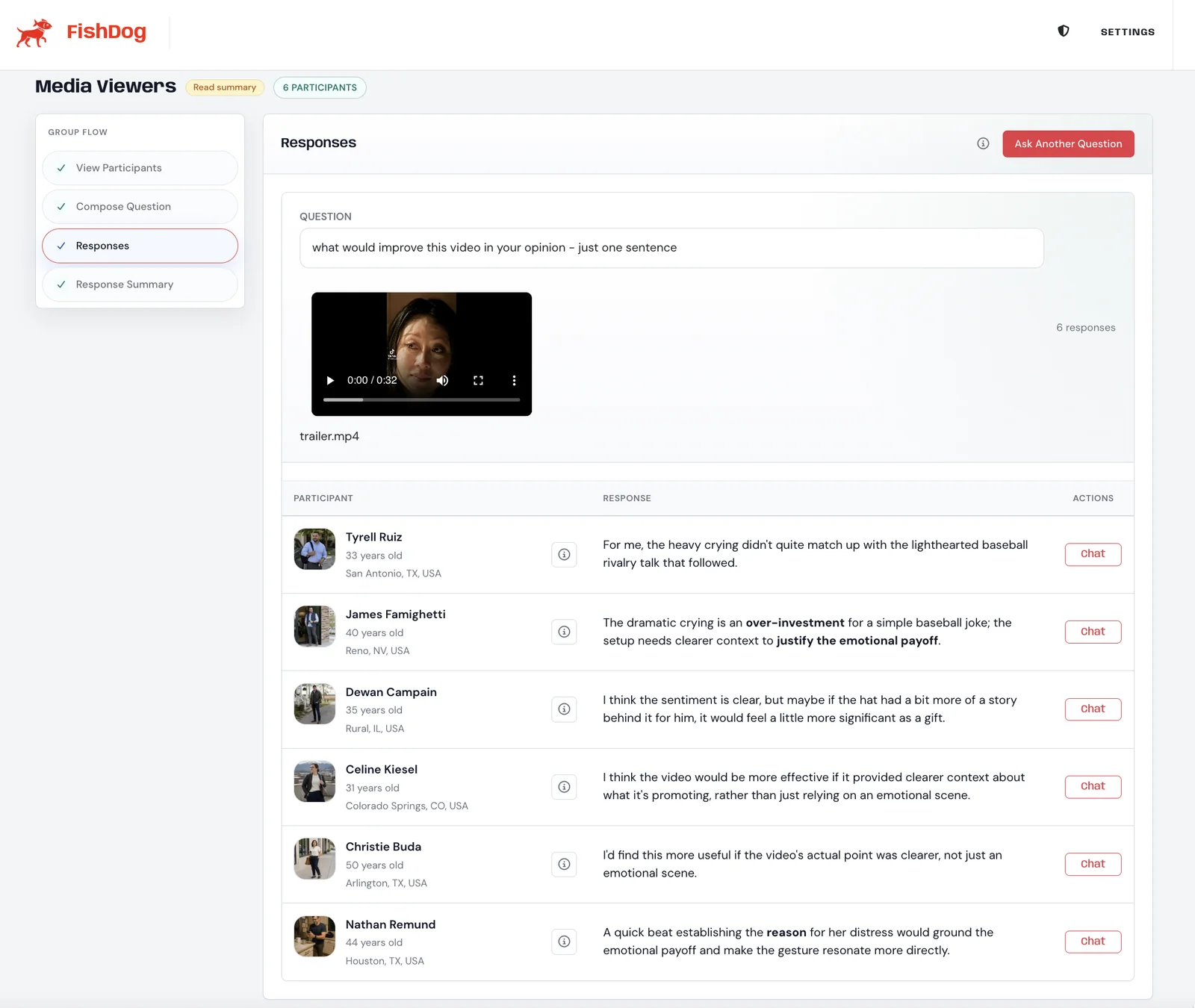
A research-group question can now carry a single video attachment — MP4, MOV or WebM, up to 200 MB. The platform processes the clip natively, without an intermediate transcription step or frame-sampling caveats, and routes the question and the video together to every persona on the panel. Responses return in the same format you already see for text questions: a per-persona reaction with their age and location surfaced, and a follow-up chat option on every individual response.
One video, many viewers
The interesting thing about the panel mechanic is the parallelism. A panel of ten personas reacting to the same trailer is a synthetic ten-person focus group that returns in minutes rather than weeks. We have tested with groups of ten, and the responses range across the lens you would expect from a mixed panel — emotional payoff, brand fit, pacing, mood, framing — in a sentence or two each.
How to use it
Open a research group on a subscription with video access enabled.
Compose your question. Drop the video file into the attachment area alongside the question text.
Select your panel — between one and the full group of personas.
Submit. Each persona answers individually; you can open a follow-up chat on any individual response.
The video stays scoped to the question and the organisation that owns it. Generic public media links are not served for video — every render path is authenticated and tied to the question that holds the clip.
What it is useful for
The first wave of expected use cases:
Video advertisement testing. Agencies and brand teams stress-testing a 15s or 30s spot before a media buy, against a synthetic panel matched to the target buyer.
Trailer and short-form testing. Film and television trailers, sizzles, episode openers, social shorts.
Episode and scene-by-scene feedback. Scripted-content teams testing pilots, episode arcs and single scenes against a defined viewer demographic.
Media-fit and brand-fit checks. Production companies and brand teams validating tone, pacing and emotional register against a viewer profile.
The intended buyers are media companies, streaming services, production houses, videographers, media producers, and the research arms of agencies and brands. The v0.1 deployment is sized for Disney-shape unaired-trailer testing, Netflix-shape short-form testing, and production-house viewer-fit checks.
A note on naming
Frontier vision models will describe what they see in a clip in detail, but they will decline to name specific brands, copyrighted characters or real people from the visual content alone. Frame questions as reactions (“how does this scene land for you?”, “what would make this stronger?”) rather than identifications (“what brand is this?”). The persona will tell you what they thought, in their voice, with their context — they will not name the IP for you.
What is next
Multi-video questions, longer clips beyond the v0.1 caps, and external-API access for video are tracked for v0.2 once we have watched a month of production traffic.