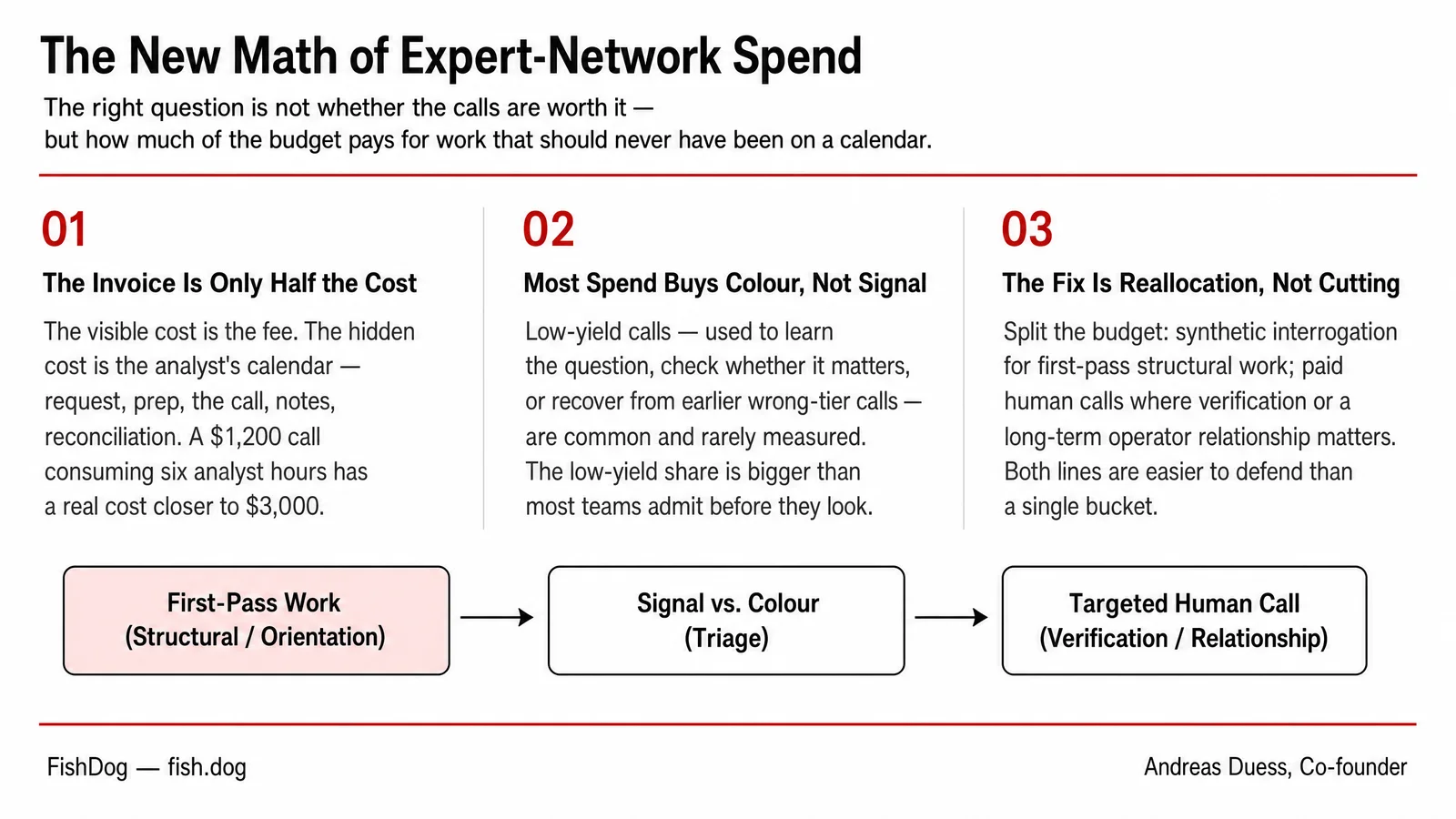
The New Math of Expert-Network Spend
I have signed off on the "external research" line item on more client budgets than I want to remember. The number was al...
Read ArticleTag: AI Research
AI research as a discipline did not exist as a category five years ago. The 2023 Stanford generative agents paper showed it was possible. The 2024 wave of platforms showed it was buildable. The 2026 enterprise traction showed it was useful. The articles in this collection cover the foundational thinking: how synthetic personas are constructed, what the Stanford paper actually said, why coding agents exposed the need for AI feedback loops, and where the field is going next.
These pieces are written for readers who want to understand the substrate, not just the surface. Buyers comparing platforms benefit from knowing what "95% accuracy" actually measures, what a persona panel is actually grounded in, and what the academic literature says about the limits of the approach. The articles here are foundational; the comparison and methodology articles in the competitor analysis collection build on this base.
What you'll find
Read the methodology, then run a study at fish.dog
I have signed off on the "external research" line item on more client budgets than I want to remember. The number was al...
Read Article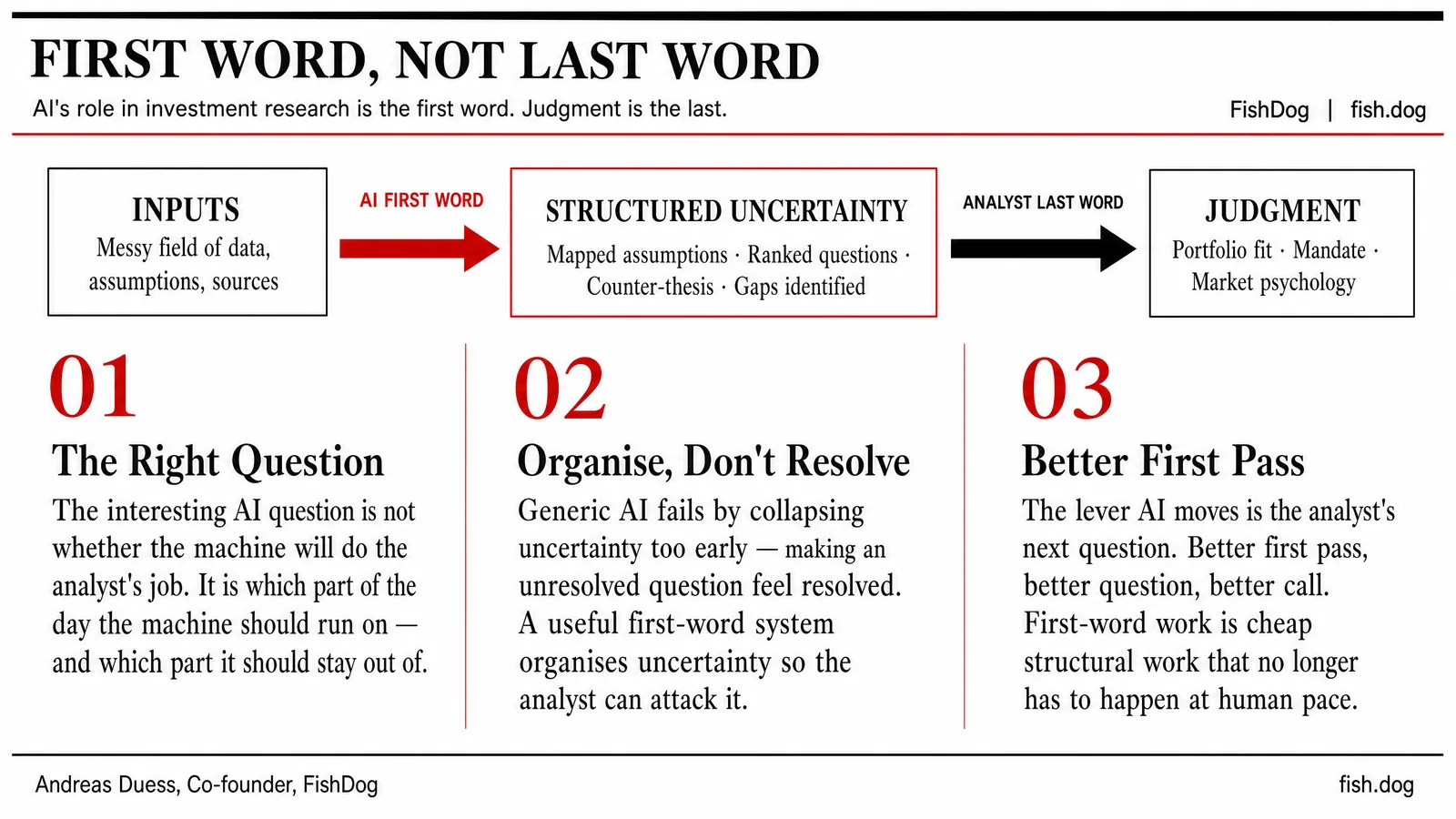
For the last two years I have been using AI in my own work the same way I want analysts to use it in theirs - as the thi...
Read Article
I have been in enough boardrooms where a research deck got demolished by a single question to know what the question loo...
Read Article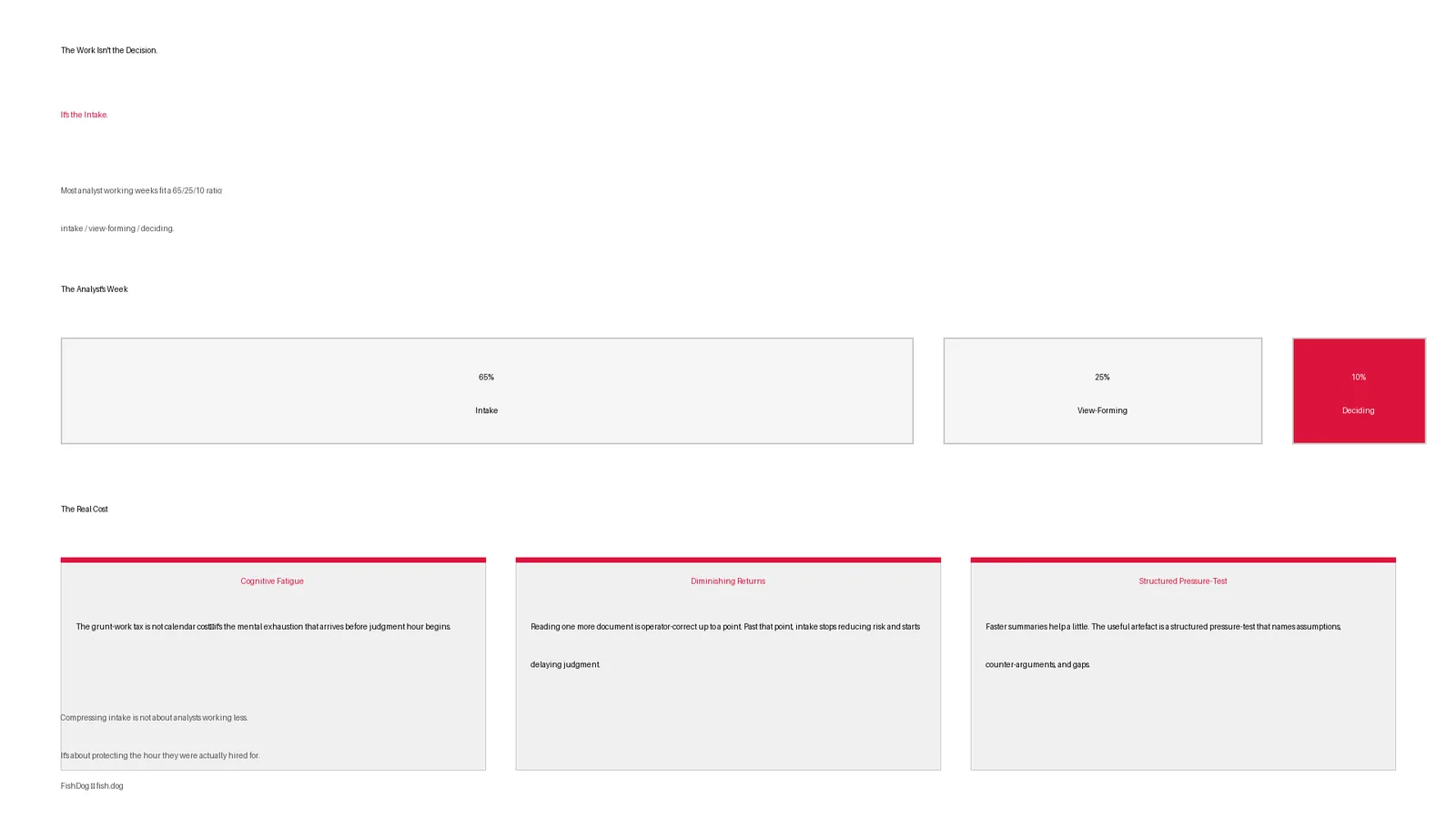
I have been a buyer of outside research for clients for twenty-five years. The mechanics have changed five times over th...
Read Article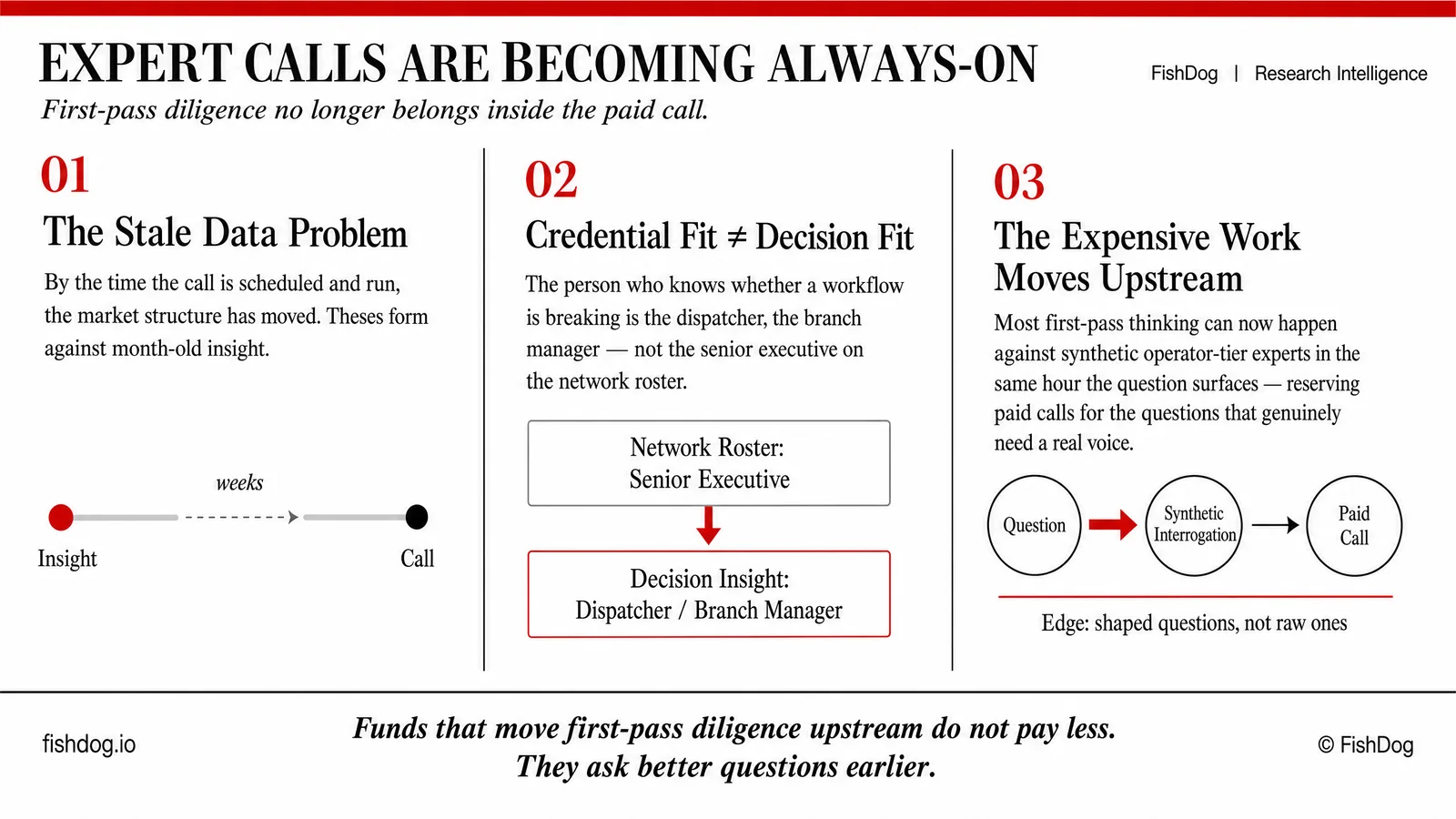
Expert calls have been the centre of gravity of hedge-fund first-pass diligence for fifteen years. That is starting to b...
Read Article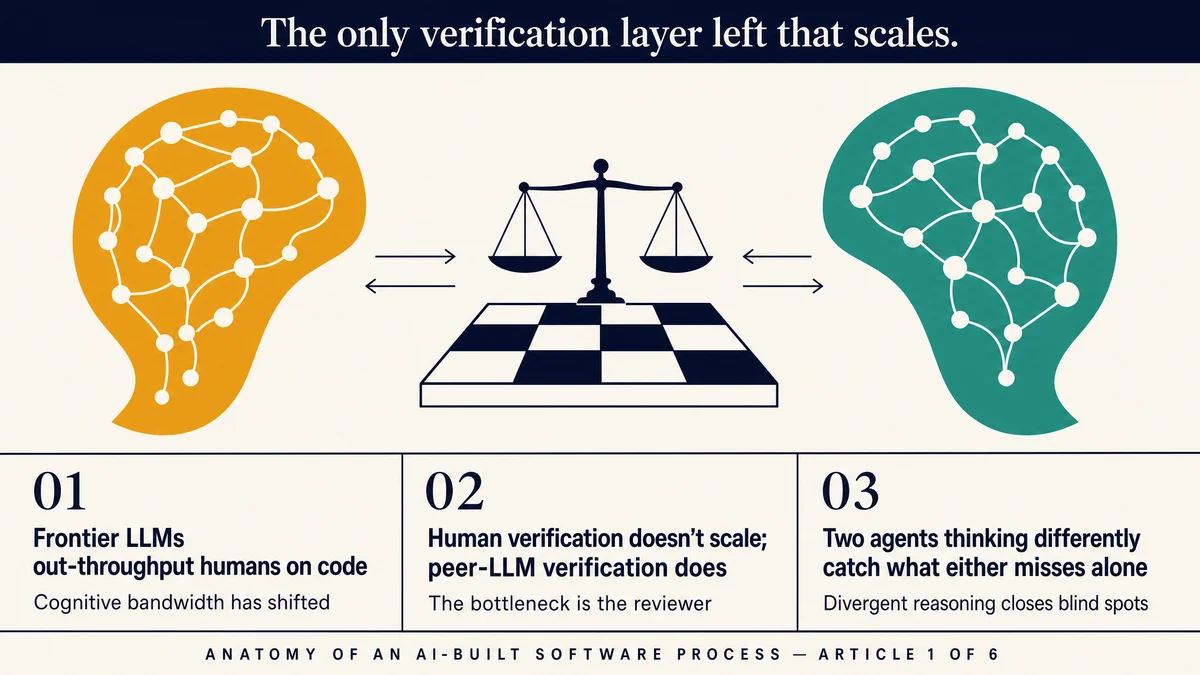
I shipped some code last week that I do not fully understand....
Read Article
For twenty years, distribution meant reaching humans through screens. Quietly, and mostly without anyone noticing, that ...
Read Article
Agents are recommending products to their humans. Not in some speculative future where autonomous systems negotiate proc...
Read Article
The peculiar thing about market research is how little it has changed. The basic model, assembling a group of people, as...
Read Article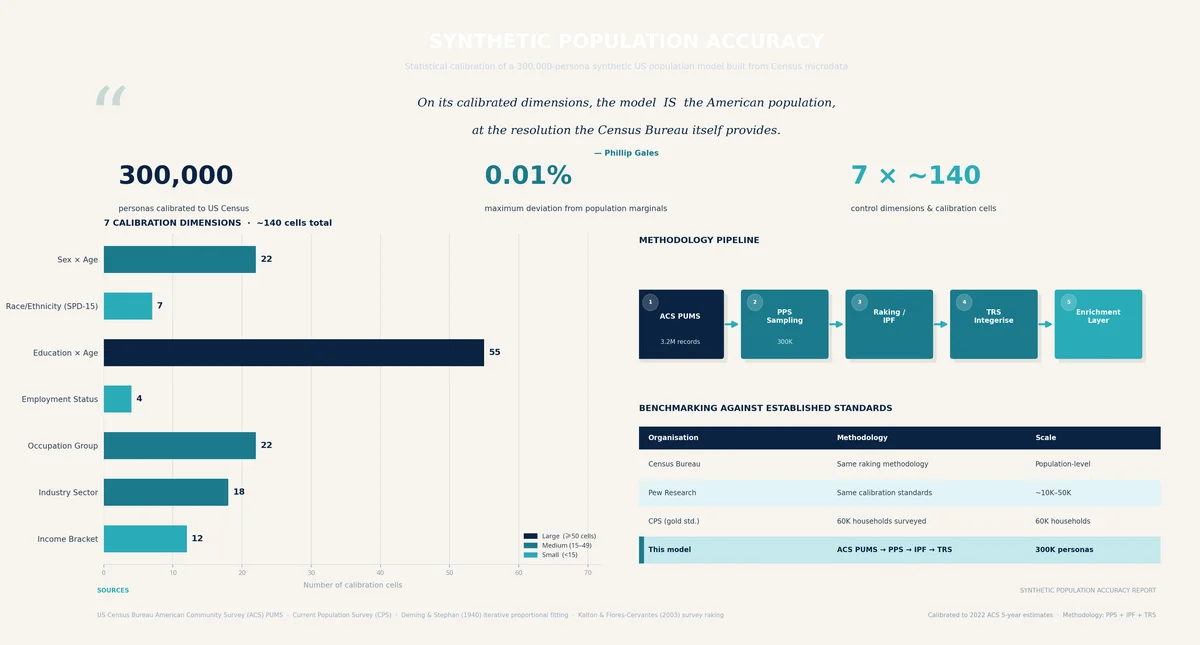
The statistics behind FishDog's synthetic research panel...
Read Article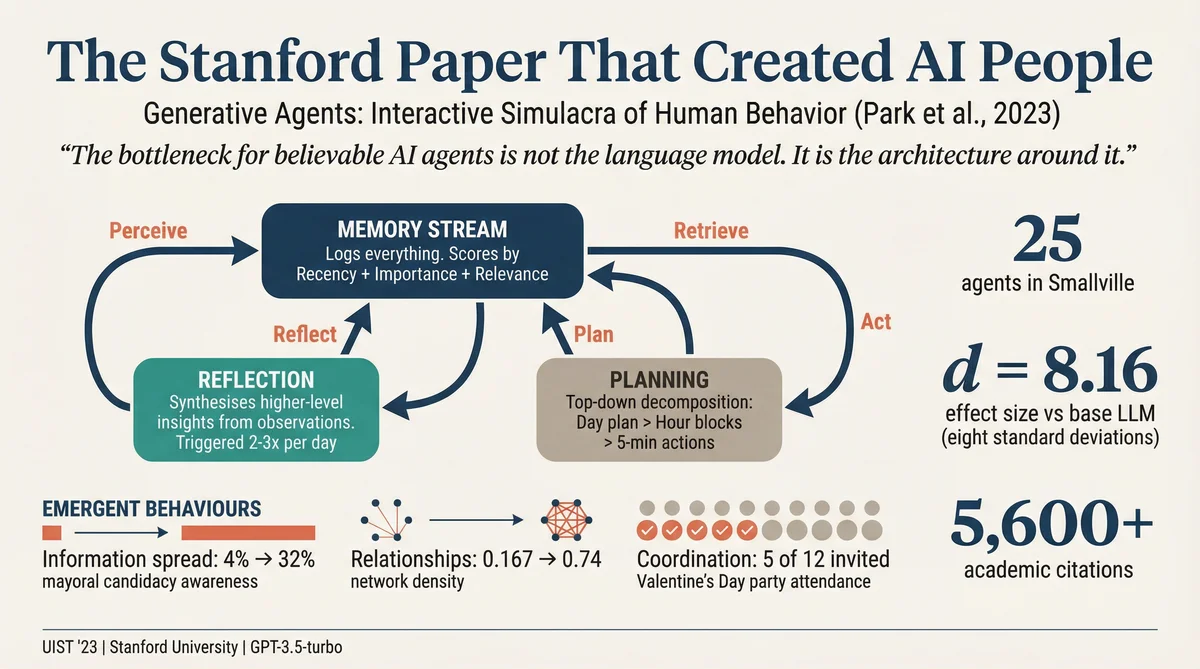
In April 2023, a research team at Stanford University published a paper that, by the standards of academic computer scie...
Read ArticleFishDog's 300,000+ AI personas are grounded in census data: each persona has a defined background, income, occupation, education, family situation, media habits, and consumer behaviour pattern, with the overall panel calibrated to match real-world demographic distributions. The how-we-built piece in this collection covers the construction methodology in detail.
Park et al's 2023 Stanford paper ("Generative Agents: Interactive Simulacra of Human Behaviour") demonstrated that LLMs could simulate believable human social behaviour at scale by combining memory, reflection, and planning components. The article in this collection unpacks the paper's contribution and what subsequent commercial platforms built on top of it.
Accuracy depends on the use case. For execution-level questions (messaging, pricing, feature rankings) AI personas perform within 5-15 percentage points of traditional research. For category-creating innovation, where lived human experience matters, the gap is wider. The methodology pieces in this collection cover what the headline numbers actually measure.
Coding agents have collapsed the time-to-build for software. The time-to-learn (do users want this? is the messaging right?) has not collapsed proportionally. AI humans — synthetic personas grounded in real demographic data — provide feedback fast enough to match agent-driven build velocity. The long-form essay in this collection makes the argument in full.
Signal from our synthetic populations, product updates, and the occasional hot take. No spam.